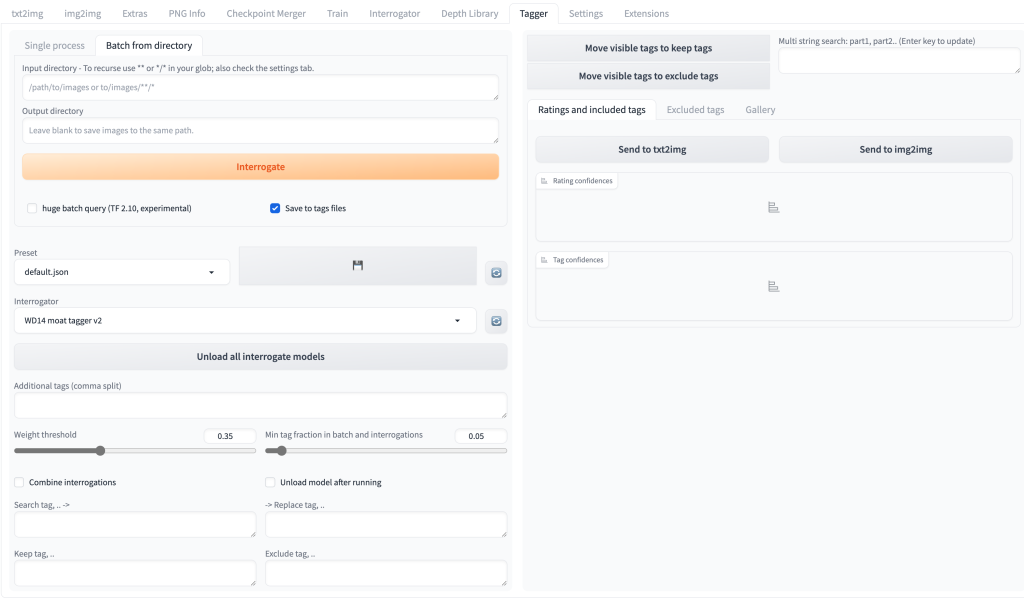
설치 후에, WEBUI 를 재실행하면 ‘Tagger’ 라는 탭이 생성되며, 여기서 이미지 데이터의 경로를 지정해주고 자동으로 프롬프트 태깅을 진행할 수 있으며,
수동으로 태그를 지정하거나, 규칙을 지정할 수도 있음.
정상 완료되면 아래와 같이 txt 파일이 생성됨.
훈련 데이터 준비
먼저 훈련 데이터셋을 설정해야 함.
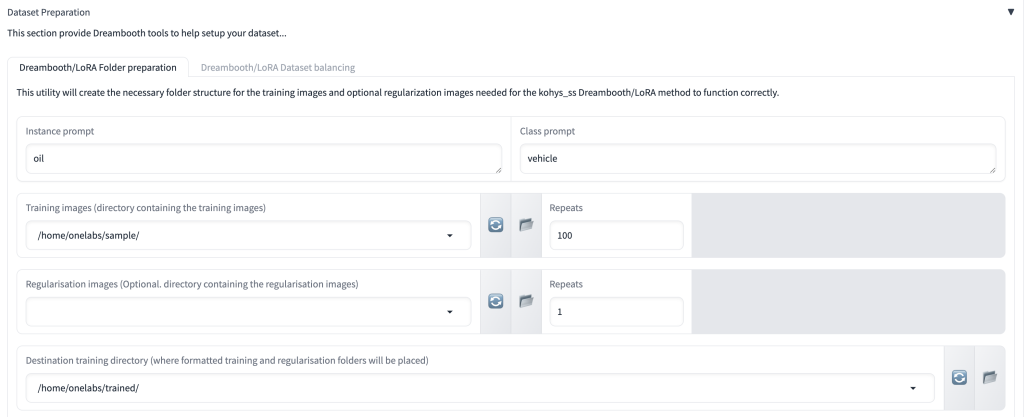
아래와 같이 어플리케이션 내의 훈련 도구를 이용하여 설정할 수 있음.
Instance prompt : 임의 단어를 지정해 토큰을 설정해줌. 적당한 단어를 입력하면 됨.
Class prompt : 훈련한 이미지 데이터의 종류를 입력함. 분류를 위해 입력하는 것이므로, 적당한 단어를 입력하면 됨.
Repeats : 훈련 이미지 반복 횟수. epoch 와 적절히 분배하여 적정 steps1 이상을 달성해야 함. 일반적으로 1000 이상의 스텝이 필요한 것으로 알려져 있으며, 이미지 수나 품질에 따라 더 많이 필요한 경우도 있음.
steps : (number of images x number of repeats) x number of epochs / batch size ↩︎
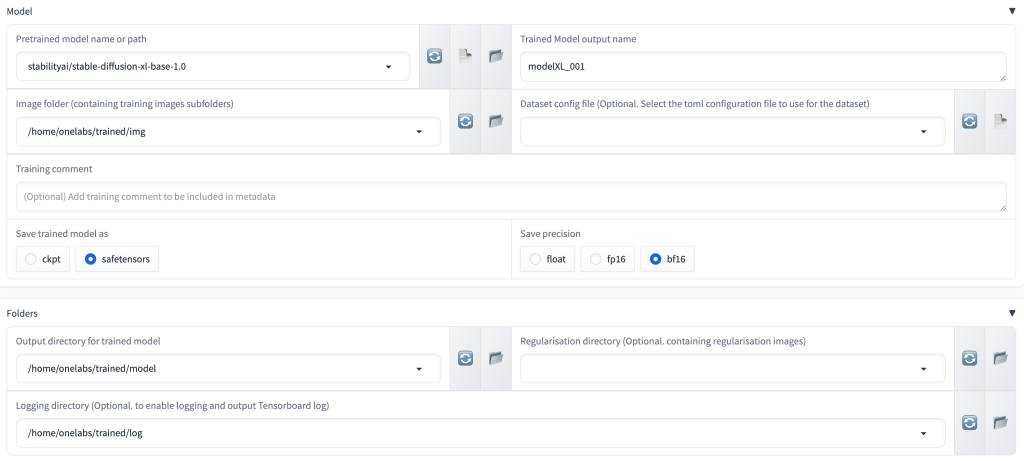
그리고 소스 모델과 폴더 설정을 해줌.
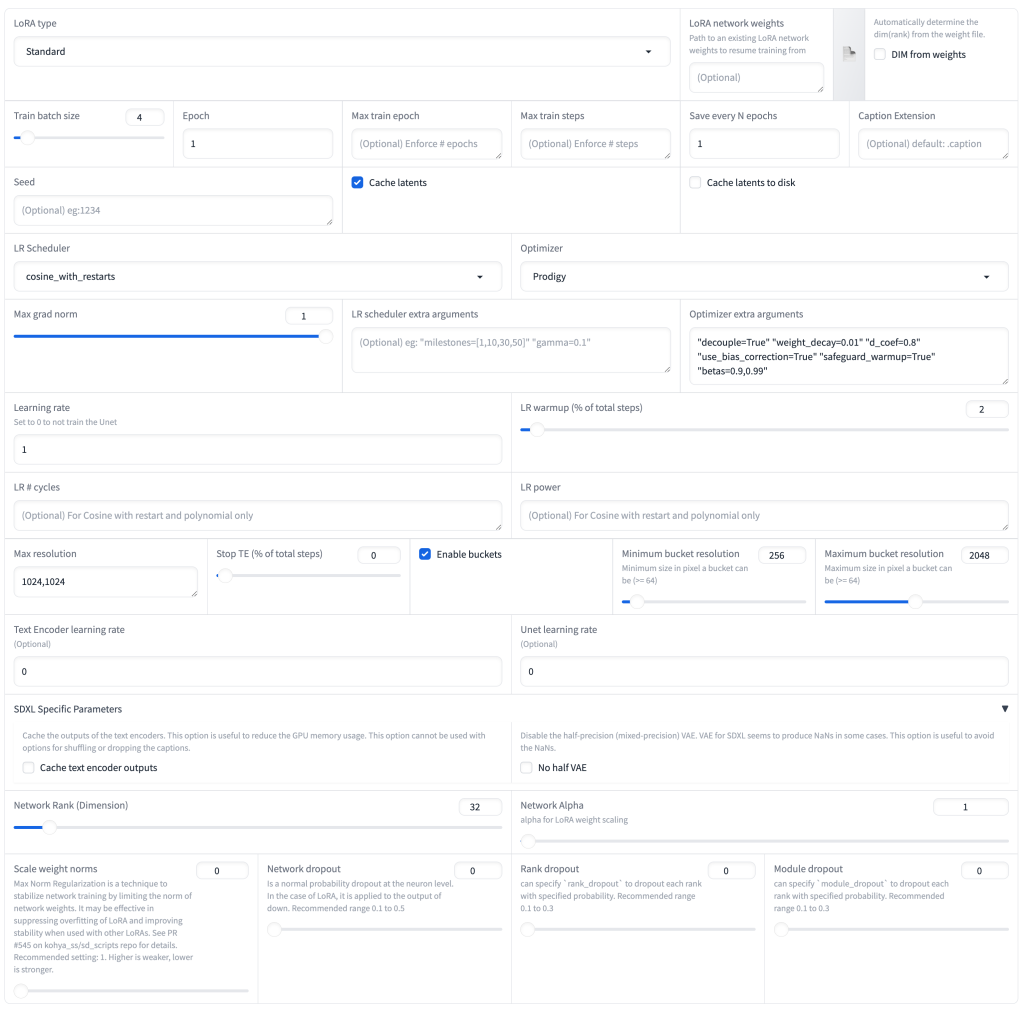
하이퍼파라미터 설정
하이퍼파라미터는 아직도 많이 연구되고 있으며, 완벽한 셋팅이 있다기보다는 기본적으로 사용하는 셋팅을 찾아두고, 각 데이터셋에 맞게 설정을 바꿔가면서 학습해보면 좋음.
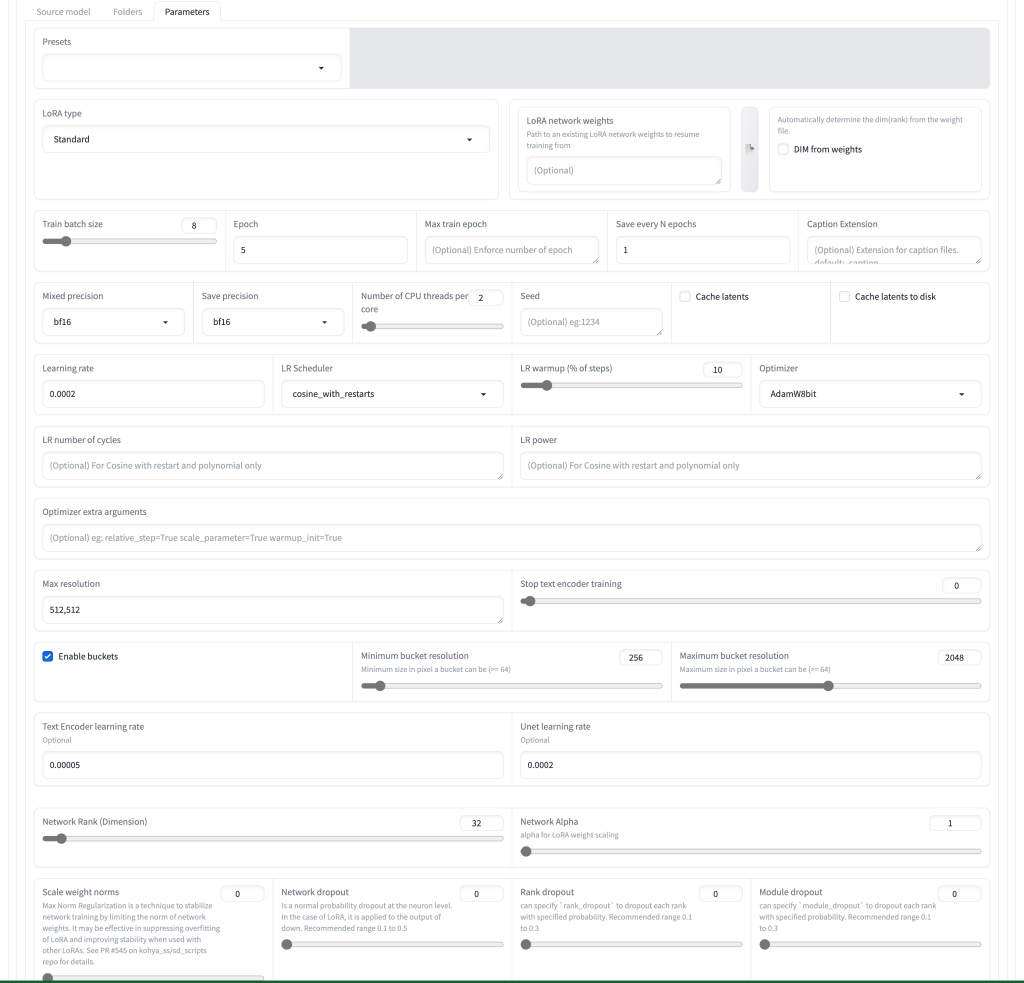
Learning rate : 높으면 빠르지만 학습이 불안정(과적합)하며, 낮으면 안정적이지만 느리며 학습량이 부족할 수 있음. extra arg 를 사용할 경우에는 learning rate 만 조절할 수 있음. 보통 Learning Rate와 U-Net Learning rate 는 0.0001 ~ 0.0002 정도를 많이 사용하며, Text Encoder Learning rate 는 0.00001~0.00005 정도를 많이 사용함.
Network Rank, Alpha : Rank 는 훈련할 Unet 과 Text Encoder 의 파라미터 수를 나타냄. 특수한 경우가 아니면 8~32 로 설정함. Alpha 는 일반적인 학습에서 1 로 사용하여도 무방함.
batch size : 전체 학습셋을 몇개의 배치로 시행함을 뜻하며, vram 의 크기에 따라 2배수로 설정함
epoch : 학습셋을 몇번 반복할지를 뜻함. epoch 수 만큼 학습 결과물이 출력되기에, 중간 결과를 확인하며 학습할 수 있음.
Optimizer : AdamW8bit 을 일반적으로 많이 사용하며, 최근엔 DAdaptation, Prodigy 와 같은 적응형도 많이 사용되고 있음.
LR Scheduler : cosine with restarts 가 가장 일반적이며, 일부 Optimizer 에서는 constant 를 사용해야하는 경우도 있음.
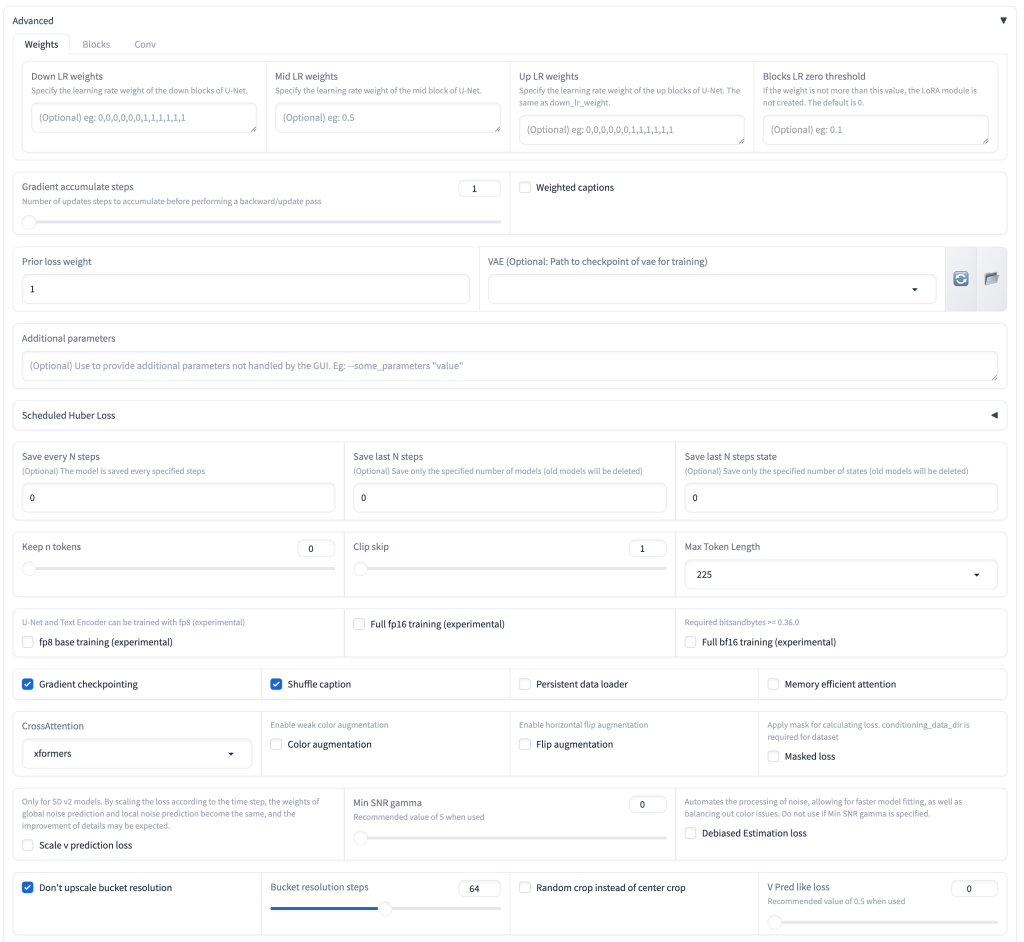
Gradient checkpointing : vram 사용량을 줄이는 대신 학습 속도가 느려짐 Persistent data loader : vram 사용량을 줄이는 대신 학습 속도가 느려짐 Shuffle Caption : 캡션의 순서를 임의로 섞어서 태그가 골고루 영향을 주도록 해줌. Color augmentation : 학습 이미지의 수가 적을 경우, 학습 이미지의 색상을 임의로 변경하여 사용 Flip augmentation: 학습 이미지의 수가 적을 경우, 랜덤하게 학습 이미지를 뒤집어서 사용
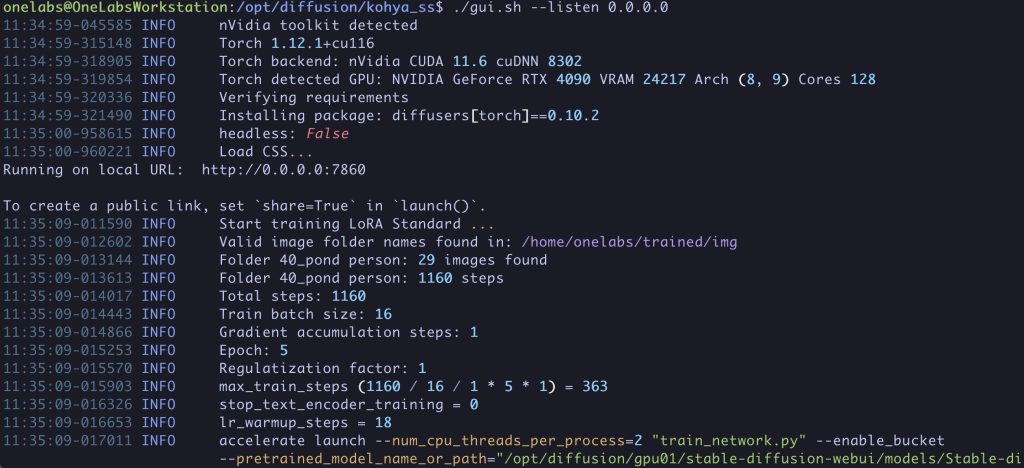
모델 훈련 시행
생성된 safetensor 파일을 ./models/Lora 디렉토리로 옮겨서 적용할 수 있음.



답글 남기기