목차
개요
AWS 에서 제공하는 정보를 더 보기 좋게 정리하고, 나아가 AWS 에서 제공하지 않는 정보를 포함하여 인프라 구성 시 고려할 사항에 대해 정리함
기본정보
인스턴스의 기본 스펙은 아래의 페이지에 명시되어 있다.
https://aws.amazon.com/ko/ec2/instance-types/
하지만 클라우드에 사용된 상세 부품 내역이나 스펙에 대해서는 공개되어 있지 않음
따라서 AWS 에서 공개한 스펙 외에는 CLI 에서 시스템 명령어를 통해 확인하거나, 벤치마크 자료를 참조해야 함.
인스턴스 네이밍
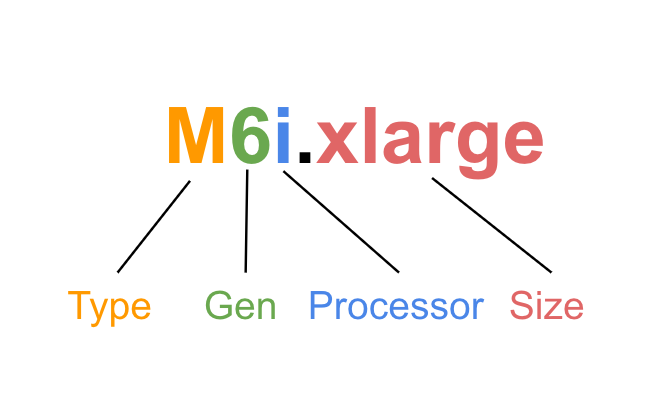
Type
사용 사례 및 워크로드에 따라 분류한 인스턴스 유형. CPU, 메모리, 스토리지 및 네트워킹에 따라 모두 다르게 구성되어 있음
Gen
인스턴스의 세대를 분류하는 표기이며, 숫자가 높을 수록 최신 세대의 인스턴스이다. 최신 세대의 인스턴스는 최신 부품 및 기술을 사용하였으므로, 성능 및 비용 효율이 전세대보다 뛰어남
Processor
어떤 CPU 를 사용하였는지를 나타냄. 다른 스펙이 동일하여도(코어수, 대역폭 등) CPU 종류에 따라 다른 성능 효율을 낼 수 있음.
다른 하드웨어가 확장된 인스턴스의 경우에도 여기에 접미어가 추가됨
Size
인스턴스 크기를 나타냄. 크기에 비례하여 코어수, 메모리, 네트워크 및 스토리지 대역폭이 상승함
인스턴스 종류
범용
M type (main)
EC2 인스턴스에서 가장 먼저 출시된 타입이며, 일관 워크로드에 좋으며 가장 균형있는 스펙을 제공함
애플리케이션 서버, 게이밍 서버, 마이크로서비스, 중형 데이터베이스, 캐싱 플릿 등 다양한 범용 워크로드를 폭넓게 지원하며 강력한 성능과 가격 대비 성능 이점을 제공함
T type (tiny or turbo)
CPU 평균 사용량이 낮은 워크로드에 대응하기 위해 만들어졌음
M type 및 C type 에서 제공하지 않는 medium(2/4) 이하의 사이즈도 제공하지만, n type 이나 d type 같은 고성능 옵션은 제공하지 않음
서비스 평균 사용률을 분석하여 기존 사용률을 초과하지 않는다면 T type 인스턴스도 M type 와 같은 범용 인스턴스로 분류되므로 이론적인 성능은 부족하지 않음
- T type 의 프로세서가 M type 의 프로세서보다 구세대 프로세서지만, 클럭 수나 연산처리능력에 큰 차이가 없음
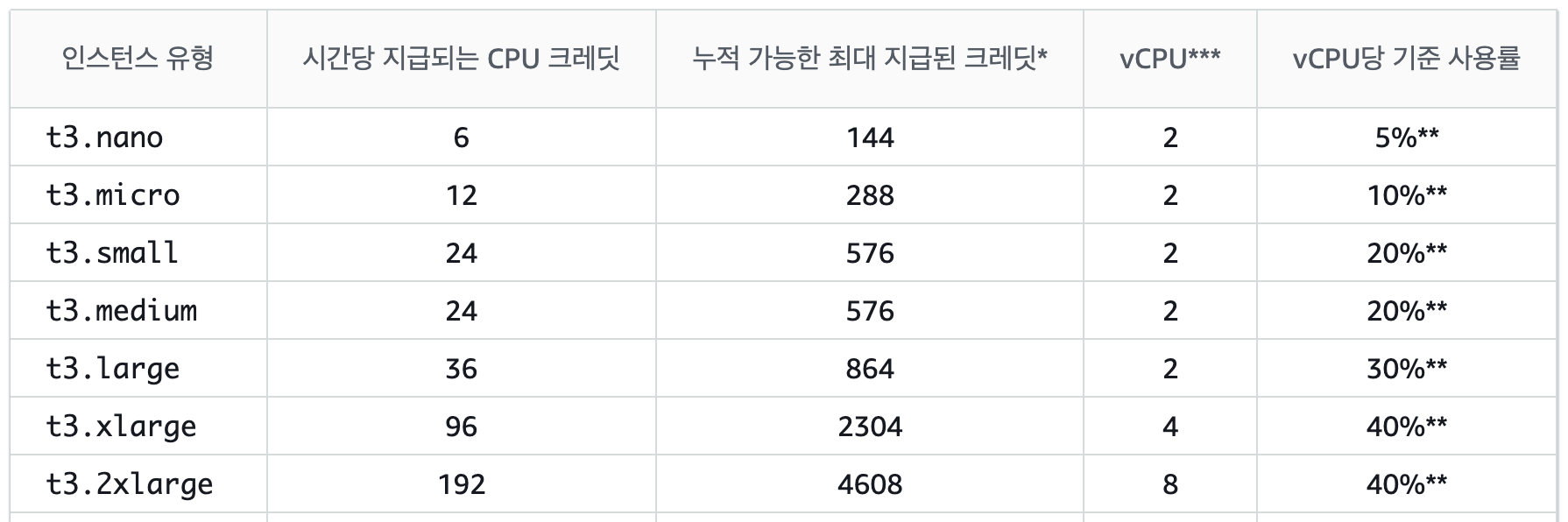
버스팅 크레딧 제공
- T 타입은 소유한 크레딧 내에서만 동작됨
- 지급되는 크레딧이 소비되는 크레딧보다 많을 경우, 크레딧이 적립됨
- 적립된 크레딧이 점점 감소하여 기준 사용률까지 수렴할 경우, 기준 사용률 이상으로 버스팅할 수 없음
- 표준 모드에서 소유한 크레딧이 모두 사용될 경우, t3.micro 기준으로 CPU 사용률이 10% 로 고정됨
- 무제한 모드를 사용할 경우에는 기준 사용률로 고정되지 않는 대신에, 추가 요금이 발생함
- 크레딧 사용량은 1개의 vCPU 에서 100% 사용률로 1분간 유지될 경우, 1개의 크레딧을 소비함
- ex.) t3.micro 에서 50% 사용률을 1분간 유지했다면, 1개의 크레딧을 소비함
https://docs.aws.amazon.com/ko_kr/AWSEC2/latest/UserGuide/burstable-credits-baseline-concepts.html
* 인스턴스 사이즈에 비례하여, 소유하는 크레딧 및 기준 사용률이 다름

https://d1.awsstatic.com/whitepapers/t2-std-cpu-credits.pdf
* 크레딧 사용량은 상기 기준으로 계산됨
컴퓨팅 최적화
C Type (compute)
M type 보다 동일 비용 대비 더 많은 vCPU 를 제공하여, 메모리에 비해 CPU 성능이 더 많이 필요한 워크로드에 적합함
또한 M type 의 프로세서보다 클럭 수 및 연산처리능력이 높으며, Turbo Boost 를 지원함
고성능 컴퓨팅(HPC), 일괄 처리, 광고 게재, 동영상 인코딩, 게임, 과학적 모델링, 분산 분석 및 CPU 기반 기계 학습 추론과 같이 컴퓨팅 집약적인 워크로드에 상당한 가격 대비 성능을 제공함
메모리 최적화
R Type (RAM)
메모리 최적화 인스턴스.
M type 보다 동일 비용 대비 더 많은 메모리를 제공하여, 메모리 성능이 많이 필요한 데이터 베이스 및 인메모리 데이터베이스, Spark 및 Presto 와 같은 실시간 빅데이터 처리에 적합함
스토리지 최적화
I Type (IOPS)
높은 I/O 인스턴스. NVMe 기반 SSD 를 기본 지원하며, 낮은 지연 시간 및 높은 IOPS 성능을 제공함.
하둡 분산 컴퓨팅, 대량 병렬 처리 데이터 웨어하우징, NoSQL 데이터베이스 및 로그 프로세싱 애플리케이션(Elasticsearch) 등 매우 큰 데이터 집합에 대한 고순차 읽기 및 쓰기 액세스를 요구하는 워크로드에 적합함
D Type (dense)
고밀도 스토리지 인스턴스. HDD 기반 로컬 스토리지와 높은 디스크 처리량을 제공하며, 가격 대비 디스크 처리량 성능이 가장 우수함
추상화된 블록 레벨 스토리지를 제공하는 EBS 와 달리 고밀도 스토리지는 직접 연결된 고성능 스토리지를 제공함
하둡 분산 컴퓨팅 및 MPP 데이터 웨어하우징과 같은 대규모 데이터 세트를 위해 저비용 스토리지 및 높은 순차 읽기/쓰기 액세스가 필요한 애플리케이션에 최적화됨
가속화된 컴퓨팅
P Type (pictures)
범용 GPU 컴퓨팅 인스턴스. 기계 학습 훈련 및 고성능 컴퓨팅을 제공함
ML/DL 성능 최적화를 위한 새로운 스트리밍 멀티프로세서(SM) 아키텍처, 2세대 NVIDIA NVLink 고속 GPU interconnect, 효율성 향상을 위해 정교하게 튜닝된 HBM2 메모리를 비롯한 새로운 기능이 다수 추가
인공 지능(AI), Machine Learning(ML), 딥 러닝(DL) 및 HPC(고성능 컴퓨팅) 애플리케이션에 활용
- 최대 8개의 최신 세대 NVIDIA Tesla v100 를 제공 (P3 기준)
G Type (graphics of GPU)
그래픽 집약적 애플리케이션을 위한 GPU 그래픽 인스턴스. NVIDIA GRID 가상 워크스테이션 기능과 H.265(HEVC) 하드웨어 인코딩을 지원
3D 시각화, 그래픽 집약적 원격 워크스테이션, 3D 렌더링, 애플리케이션 스트리밍, 비디오 인코딩 및 기타 서버 측 그래픽 워크로드에 활용
- NVIDIA Tesla M60 GPU (G3 기준)
inf Type (inference)
예측, 이미지 및 비디오 분석, 텍스트 및 문서 분석, 음성, 번역 등의 고급 AI 추론을 위한 특수 유형
- TensorFlow, PyTorch, MXNet 등 인기 있는 ML 프레임워크 중 하나에서 P타입 등의 GPU 인스턴스를 사용하여 모델을 구축하고 학습시킴으로써 기계 학습 워크플로우를 시작했다면, 학습된 모델을 ML 프레임워크의 API를 통해 Inferentia용 소프트웨어 개발 키트인 Neuron을 호출하여 모델을 Inferentia 칩에서 실행할 수 있도록 컴파일하고 Inferentia의 메모리로 로드한 후 추론 호출을 실행할 수 있음
- 기계학습 추론을 위한 전용칩 Inferentia 을 탑재하여 짧은 지연 시간과 높은 처리량을 제공함
그외 지원 기능
| 접미어 | 특징 | 비고 |
| i | 인텔 제온 프로세서 사용 | 타입/세대/사이즈에 따라 다른 프로세서 사용 |
| a | AMD EPYC 프로세서 사용 | 타입/세대/사이즈에 따라 다른 프로세서 사용 |
| g | AWS Graviton 프로세서 사용 | 현 최신세대 기준으로 Arm 기반 AWS Graviton2 프로세서 사용 |
| e | 확장된 메모리 | |
| z | 고클럭 프로세서 | |
| n | 향상된 네트워크 대역폭 지원 | |
| d | NVMe 기반 SSD 가 물리적으로 연결됨 | |
| b | EBS 최적화 인스턴스. 더 많은 대역폭과 IOPS를 제공함 |
주요 인스턴스 CPU 정보
타입 및 세대, 사이즈에 따라 사용되는 CPU 프로세서가 다름
| vCPU/Mem | 이름 | CPU 정보 | 싱글스레드 | 최대 Mhz | 출시일 | 비용 | 비고 |
| 4/8 |
c6i.xlarge |
Intel Xeon Platinum 8375C @ 2.90GHz | 2,467 | 3,500 | Q2 2021 | $0.192 | |
| m6i.large | Intel Xeon Platinum 8375C @ 2.90GHz | 2,467 | 3,500 | Q2 2021 | $0.118 | ||
| c5.xlarge | Intel Xeon Platinum 8275CL @ 3.00GHz | 2,375 | 3,600 |
Q4 2019 |
$0.192 | ||
| c5a.xlarge |
AMD EPYC 7R32 |
1,922 | 3,300 | Q4 2020 | $0.172 | ||
| 4/16 | m5a.xlarge |
AMD EPYC 7571 |
1,934 | 2,900 | Q2 2019 | $0.212 | |
| m5.xlarge |
Intel Xeon Platinum 8259CL @ 2.50GHz |
1,863 | 3,500 | Q1 2020 |
$0.236 |
||
| 2/8 | t3a.large | AMD EPYC 7571 | 1,934 | 2,900 | Q2 2019 |
$0.0936 |
|
| t3.large | Intel Xeon Platinum 8175M @ 2.50GHz | 1,903 | 2,500 | Q2 2018 | $0.104 | ||
| m4.large | Intel Xeon E5-2686 v4 @ 2.30GHz | 1,613 | 2,300 | Q4 2016 | $0.123 | ||
| m5.large | Intel Xeon Platinum 8175M @ 2.50GHz | 1,903 | 2,500 | Q2 2018 | $0.118 | ||
| 2/4 | c5.large | Intel Xeon Platinum 8124M @ 3.00GHz | 2,051 | 3,500 | Q4 2018 |
$0.096 |
|
| t3a.medium | AMD EPYC 7571 | 1,934 | 2,900 | Q2 2019 |
$0.0468 |
||
| t3.medium | Intel Xeon Platinum 8175M @ 2.50GHz | 1,903 | 2,500 | Q2 2018 | $0.052 | ||
| 2/2 | t3.small | Intel Xeon Platinum 8175M @ 2.50GHz | 1,903 | 2,500 | Q2 2018 | $0.026 | |
| 2/1 | t3.micro | Intel Xeon Platinum 8175M @ 2.50GHz | 1,903 | 2,500 | Q2 2018 | $0.013 |
- EPYC 과 Xeon 는 단순 싱글 스레드의 처리 능력 외에도 avx2 및 avx-512 등의 명령어셋 지원 여부 차이가 있음
- Turbo Boost 의 경우 C 타입 인스턴스 외에서도 포함되는 경우가 있음
- EC2 인스턴스의 가상화 방식
- AWS 는 5세대 인스턴스부터 KVM 을 기반으로 개량한 Nitro System 을 도입함(M5/C5/T3)
- Nitro System 을 도입하며 HVM(전 가상화) 방식의 Guest OS 만 지원하고 있음
- vCPU 은 실제 코어에서 할당되는 하이퍼 스레드 코어임 (일반적으로 *2 가 됨)
- vCPU, CPU/Mem/스토리지 효율에 따른 비용
- vCPU 당 비용
- CPU 의 싱글 스레드, 메모리 대역폭 및 스토리지 IOPS 효율 당 비용
벤치마크
비교 대상 인스턴스 선정
c5.large vs c5a.large
- 가장 작은 사이즈의 C 타입 인스턴스
- Intel 프로세서와 AMD 프로세서의 비교
- 현재 6세대 인스턴스에 AMD 프로세서는 나오지 않은 관계로 5세대 인스턴스로 진행
m5.xlarge vs m5a.xlarge
- 주로 사용되는 타입 및 사이즈이며, 많은 메모리를 사용하는 환경에서의 테스트
- Intel 프로세서와 AMD 프로세서의 비교
- 현재 6세대 인스턴스에 AMD 프로세서는 나오지 않은 관계로 5세대 인스턴스로 진행
c5.2xlarge vs c5a.2xlarge
- 많은 스레드를 사용하는 환경에서의 테스트
- Intel 프로세서와 AMD 프로세서의 비교
- 현재 6세대 인스턴스에 AMD 프로세서는 나오지 않은 관계로 5세대 인스턴스로 진행
테스트 방법
OS 는 ubuntu 20.04 로 설치하여 진행함
CPU 성능
- geekbench 로 싱글 및 멀티코어 점수를 측정
- https://browser.geekbench.com/v5/cpu/12441253
- https://browser.geekbench.com/v5/cpu/12441120
- https://browser.geekbench.com/v5/cpu/12803926
- https://browser.geekbench.com/v5/cpu/12804114
- https://browser.geekbench.com/v5/cpu/12806645
- https://browser.geekbench.com/v5/cpu/12806799
메모리 성능
- STREAM 으로 메모리의 대역폭 및 연산 시간를 측정
디스크 성능
- 디스크에 랜덤 파일을 생성하고 읽어들이는 속도를 측정함
- dd if=/dev/zero bs=1024 count=100 of=test_file oflag=direct
- dd if=test_file of=/dev/null bs=1024
| 인스턴스 | 프로세서 | 싱글코어 | 멀티코어 | 메모리 성능 (Best Rate, Avg time) | 디스크 성능 |
| c5.large | Intel Xeon Platinum 8275CL | 979 | 1166 |
Copy : 13266.0 MB/s, 0.012272 s |
읽기 : 664 MB/s 쓰기 : 1.7 MB/s |
| c5a.large | AMD EPYC 7R32 | 980 | 1246 |
Copy : 18722.5 MB/s, 0.008618 s |
읽기 : 1.2 GB/s 쓰기 : 1.8 MB/s |
| m5.xlarge | Intel Xeon Platinum 8180M | 868 | 2022 |
Copy: 13764.5 MB/s, 0.011812 s |
읽기 : 629 MB/s 쓰기 : 1.8 MB/s |
| m5a.xlarge | AMD EPYC 7571 | 722 |
1731 |
Copy: 13256.1 MB/s, 0.012214 s |
읽기 : 869 MB/s 쓰기 : 1.5 MB/s |
| c5.2xlarge | Intel Xeon Platinum 8124M | 944 | 4334 |
Copy: 13284.7 MB/s, 0.012159 s |
읽기 : 702 MB/s 쓰기 : 1.8 MB/s |
| c5a.2xlarge | AMD EPYC 7R32 | 975 | 4525 |
Copy: 18652.2 MB/s, 0.008642 s |
읽기 : 1.3 GB/s 쓰기 : 1.4 MB/s |
* 수회 반복 테스트하여 가장 중간값을 표기
결론
단순 CPU 의 코어수, 메모리 등의 스펙만이 아닌 실제 어떤 프로세서 모델이 사용되었는지, 시스템을 구성하는 다른 부품과의 상호 관계성, 애플리케이션과의 호환성 등을 고려해야함.
가설 확인
인스턴스 타입에 따른 성능 차이가 있음
C 타입 AMD 인스턴스에서 사용된 프로세서(AMD EPYC 7R32) 에서 뛰어난 메모리 성능을 보여줌
- 실제 확인 결과 5세대에서는 C 타입 인스턴스에 고클럭을 지원하였으나(기본 클럭이 높은 모델, Turbo boost), 6세대에서는 동일한 모델의 CPU 를 사용 중인 것으로 확인됨
- 현재 확인한 내용 기준으로는 C 타입이 M 타입에 비해 고성능 컴퓨팅을 지원하는 부분보다는 비용 당 더 많은 vCPU 를 지원하는 부분에 주목하여 선택해야 함
프로세서에 따른 성능 차이가 있음
타입/세대/사이즈에 따라 다른 프로세서가 사용되며, 실제 성능은 프로세서마다 상이하므로 타입 및 제조사에 따라 일률적으로 판단하기 어려움
- 5세대 기준으로 벤치마크한 결과로는 Intel 과 AMD 의 우열이 아닌, 프로세서의 종류마다 다른 결과를 보임
- 실제 애플리케이션 성능에서는 지원 명령어셋이나 호환성에 따라 다른 결과를 보일 수 있음
- 메모리의 경우 대역폭을 제공하는 방식이 각각 다르므로 스레드/채널 수에 따라 선형적인 성능 구간을 보일 수 있음
인스턴스 선택 기준
프로젝트에 필요한 인스턴스를 선택할 경우 아래와 같은 순서로 고려할 수 있음
- 시스템 및 애플리케이션의 용도 → 범용/컴퓨팅/메모리/스토리지/가속화
- 평균 CPU 가동률 → 일반/Turbo Boost 지원/버스팅(T 타입)
- 시스템 및 애플리케이션 구동에 필요한 vCPU/Mem 의 수
- 높은 네트워크 대역폭 및 스토리지 속도의 필요성 → n/d/b
- 시스템 및 애플리케이션의 호환성 → i,a(x86)/g(Arm)
- 비용 효율성 → i(Intel)/a(AMD)
답글 남기기