개념
사용자의 의사 결정에 도움을 주기 위하여 분석 가능한 형태로 정보들이 저장되어 있는 중앙 저장소다. 정보(data)와 창고(warehouse)의 의미가 합성되어 만든 어휘
데이터 웨어하우스(DW)는 1980년대 중반 IBM이 자사의 하드웨어를 판매하기 위해 처음으로 도입했던 개념으로, IBM은 ‘정보창고’의 의미로 인포메이션 웨어하우스(Information Warehouse)라는 용어를 사용하였다.
이후 이 개념은 많은 하드웨어, 소프트웨어 및 툴(tool) 공급 업체들에 의해 이론적, 현실적으로 성장하였으며, 1980년대 후반 W.H Inmon에 의해 최초로 데이터 접근 전략으로 데이터웨어하우스 개념을 사용함으로써 많은 관심과 집중을 받게 되었다
데이터는 트랜잭션 시스템, 관계형 데이터베이스(RDMS) 및 기타 소스로부터 보통 정기적으로 데이터 웨어하우스로 들어간다. 비즈니스 애널리스트, 데이터 엔지니어, 데이터 사이언티스트들은 비즈니스 인텔리전스(BI) 도구, SQL 클라이언트 및 기타 분석 응용 프로그램을 통해 데이터에 액세스하게 된다.
- 주제 중심의 구성
- 이용자가 이해하기 쉬운 형태로 주제 지향성을 가짐
- 통합된 구조
- 데이터 속성의 이름, 코드의 구조, 도량형 단위 등의 일관성을 유지하며 전사적 관점에서 하나로 통합함
- 시계열
- 데이터 웨어하우스(DW)는 일정 기간 수집된 데이터를 갱신 없이 보관하며 일, 월, 분기, 년 등과 같은 기간 관련 정보를 함께 저장함
- 비휘발성
- 데이터 웨어하우스(DW) 내의 데이터는 일단 적재(loading)가 완료되면 읽기 전용 형태의 스냅 샷 데이터로 존재하며, 더 이상 업데이트 작업이 일어나지 않음
RDBMS 와 차이
| RDBMS | data warehouse | |
|---|---|---|
| 용도 | OLTP(온라인 트랜잭션) 워크로드 | 의사결정 및 분석 |
| 데이터 형태 | 기능별 상세 데이터 | 주제별 요약 데이터 |
| 데이터 처리 | CRUD | read only |
| 목적 | 단일 행 트랜잭션 처리 | 대용량 데이터 셋을 대상으로 복합적인 분석 쿼리를 빠르게 실행 |
ETL (Extract, Transform, Load)
원시 데이터 혹은 애플리케이션 데이터를 추출하여 정제한 후에 데이터 웨어하우스에 적재하는 모든 과정을 말함
일반적으로 데이터 정제(변환)에는 필터링, 정렬, 집계, 데이터 조인, 데이터 정리, 중복 제거 및 유효성 검사 등의 다양한 작업이 포함됨
- Extract : 하나 또는 여럿 데이터 소스로부터 데이터 추출
- Transform : 데이터 클렌징, 형식 변환 및 표준화, 통합 또는 다수 애플리케이션에 내장된 비즈니스룰 적용 등
- Load : 정제 완료된 데이터를 데이터 웨어하우스 시스템에 적재
BI (Business Intelligence)
데이터 추출/통합/리포팅을 위한 기본도구 집합. DW 에서 분석된 데이터를 통해 숨겨진 패턴을 찾아냄
아키텍처
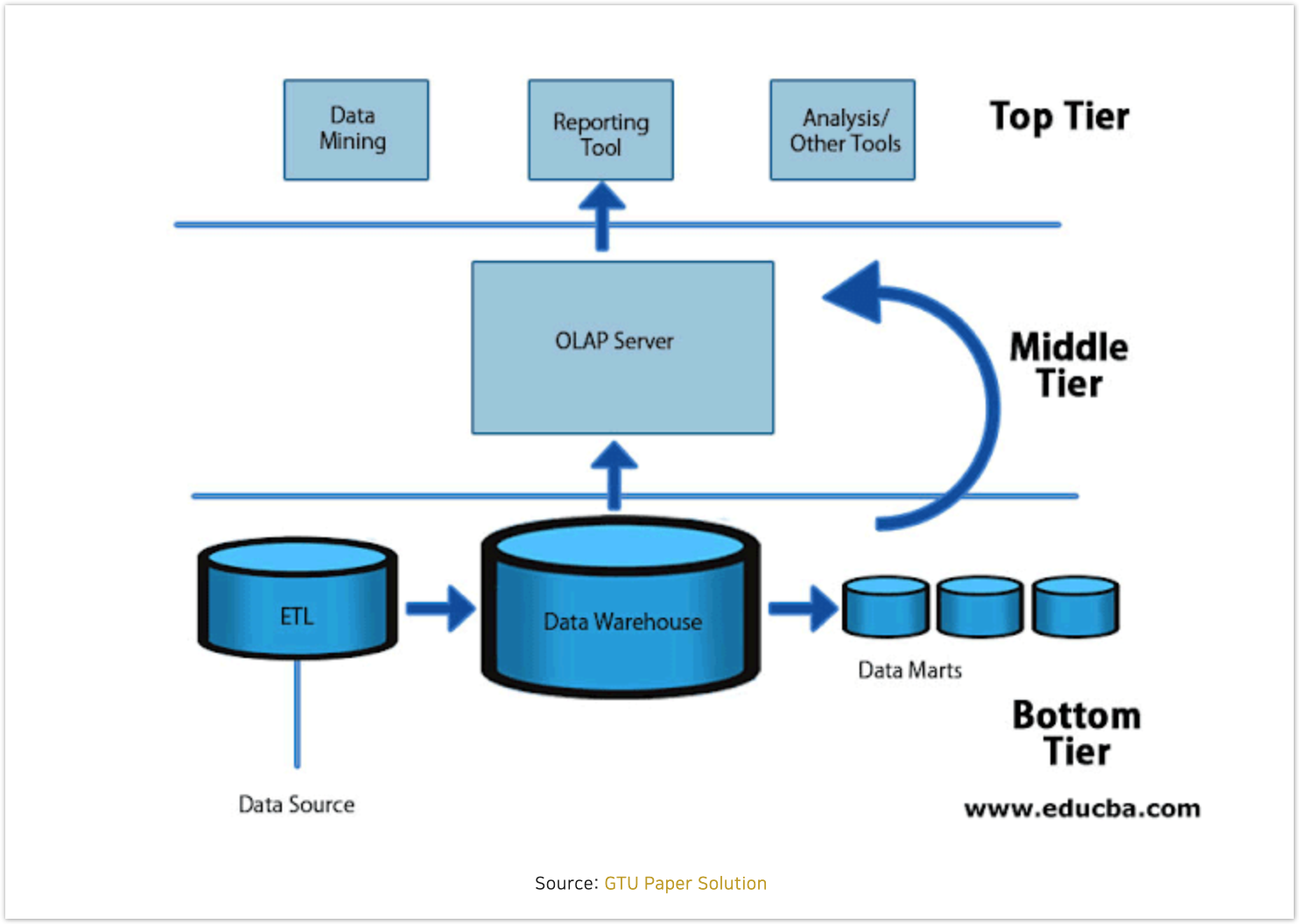
DW (Data Warehouse) 의 아키텍처는 3단계의 티어로 구성됨
- Top Tier : 통계, 분석, 데이터마이닝, AI 등을 통해 분석한 결과를 리포팅하는 프론트엔드 티어. 가시성(시각화)를 제공하는 티어. OLAP 도구에 해당
- Middle Tier : 데이터를 액세스하고 분석하는데 사용하는 분석 엔진으로 구성. OLAP 서버에 해당.
- Bottom Tier : 데이터가 로드되고 저장되는 데이터베이스 서버 티어.
OLAP (On-Line Analytical Processing)
데이터웨어하우스 활용 수단의 통칭
BI (Business Intelligence) 의 한 분야로 최종 사용자가 정보에 직접 접근해 대화식으로 정보를 분석하고 의사결정에 활용하는 과정을 말함
- MOLAP (Multi-dimensional OLAP) : MDB(다차원 데이터베이스) 를 베이스로함
- ROLAP (Relational OLAP) : RDB(관계형 데이터베이스) 를 베이스로함
OLTP (On-Line Transaction Processing)
트랜잭션을 수집하고 분류, 저장, 유지보수, 갱신, 검색하는 기능을 수행하는 실시간 거래 처리 시스템으로, 항공사의 예약시스템이나 은행의 창구업무시스템 등이 대표적이다.
OLTP 시스템에서 필요한 데이터를 추출하여 정제한 것이 데이터 웨어하우스이며, 이를 활용하는 수단이 OLAP 이다.
Data Mart
금융, 마케팅 또는 특정팀, 사업 단위의 요구를 충족시키는 데이터 웨어하우스.
규모가 더 작고, 집중적이며 사용자 커뮤니티에 가장 알맞는 데이터 요약을 포함할 수 있음
대개 데이터 마트는 데이터 웨어하우스의 일부로 구성됨
주요 Data Warehouse 서비스
Amazon Redshift
Amazon Redshift는 AWS 에서 서비스하는 클라우드 데이터 웨어하우스이다.
데이터 작업을 빠르고 간단하게 수행하고, AWS 에코시스템에 손쉽게 연결할 수 있도록 한다.
데이터 Load/Unload
- Load
- S3 : 병렬 데이터 로딩(Multipart Upload) 을 지원
- DynamoDB : Copy 명령어를 통해 DynamoDB Table 로 로딩
- EMR : Copy 명령어를 통해 병렬 로딩 지원
- Remote 호스트(온프레미스) : EC2 등의 호스트에서 복수 연결 후에, 병렬 로딩 지원
- Unload
- S3 로 증분 백업 데이터를 저장할 수 있음
컬럼 압축(Column Compression)
- DW 시스템이 스토리지에서 데이터를 읽는 크기를 줄여 IO 최소화 시키고, 쿼리 성능을 향상 시키는 주요 기능
- COPY 명령을 사용해서 Amazon Redshift로 데이터를 로딩하면 데이터 분석을 통해 최적의 압축 수행
- 압축 기능의 자동 적용을 위해 COPY 명령어 사용을 권장
데이터 분산(Data Distribution)
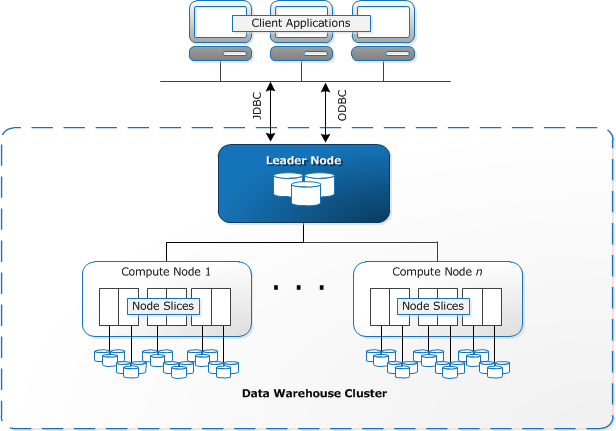
Redshift는 분산형(MPP : Massively Parallel Computer) 구조의 시스템이다.
- 클러스터는 Leader node 와 Compute node 최소 2개의 노드로 구성됨
- Compute node는 하나 이상의 slices로 구성
- 각 slices 는 데이터를 포함
쿼리는 모든 slices 들에서 병렬 수행하여 데이터를 고르게 분산함
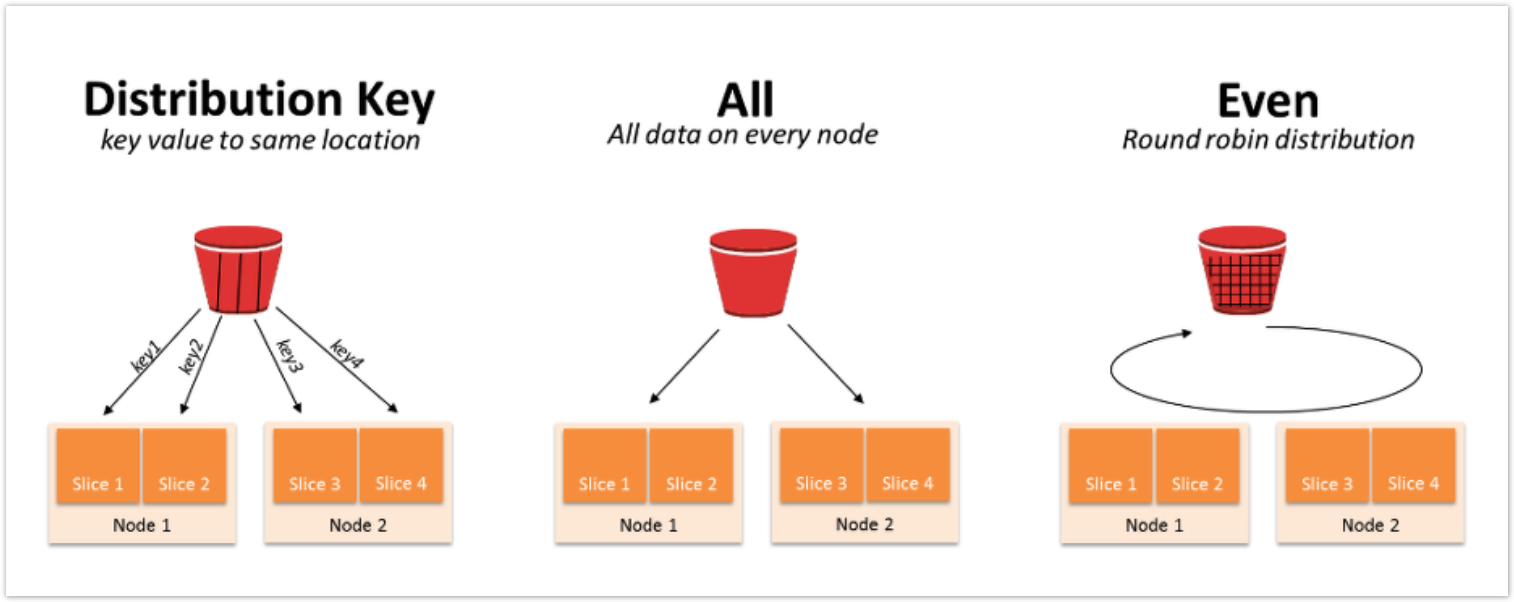
- DISTKEY(Distribution key)
- 명시적으로 지정한 컬럼을 기준으로 각 레코드의 slice 배치가 결정됨
- 컬럼 카디널리티에 따라 slice간 상당한 편차가 발생 가능함 (* 컬럼 카디널리티 : 전체 행에 대한 특정 컬럼의 중복 수치)
- ALL
- 모든 레코드가 각 컴퓨팅 노드에 동일하게 복제함
- EVEN
- 각 레코드가 slice 에 라운드 로빈 방식으로 균등하게 저장함
Spectrum 기능
데이터를 Redshift 에 적재하지 않고 S3 내에 있는 데이터 소스를 직접 쿼리할 수 있는 기능
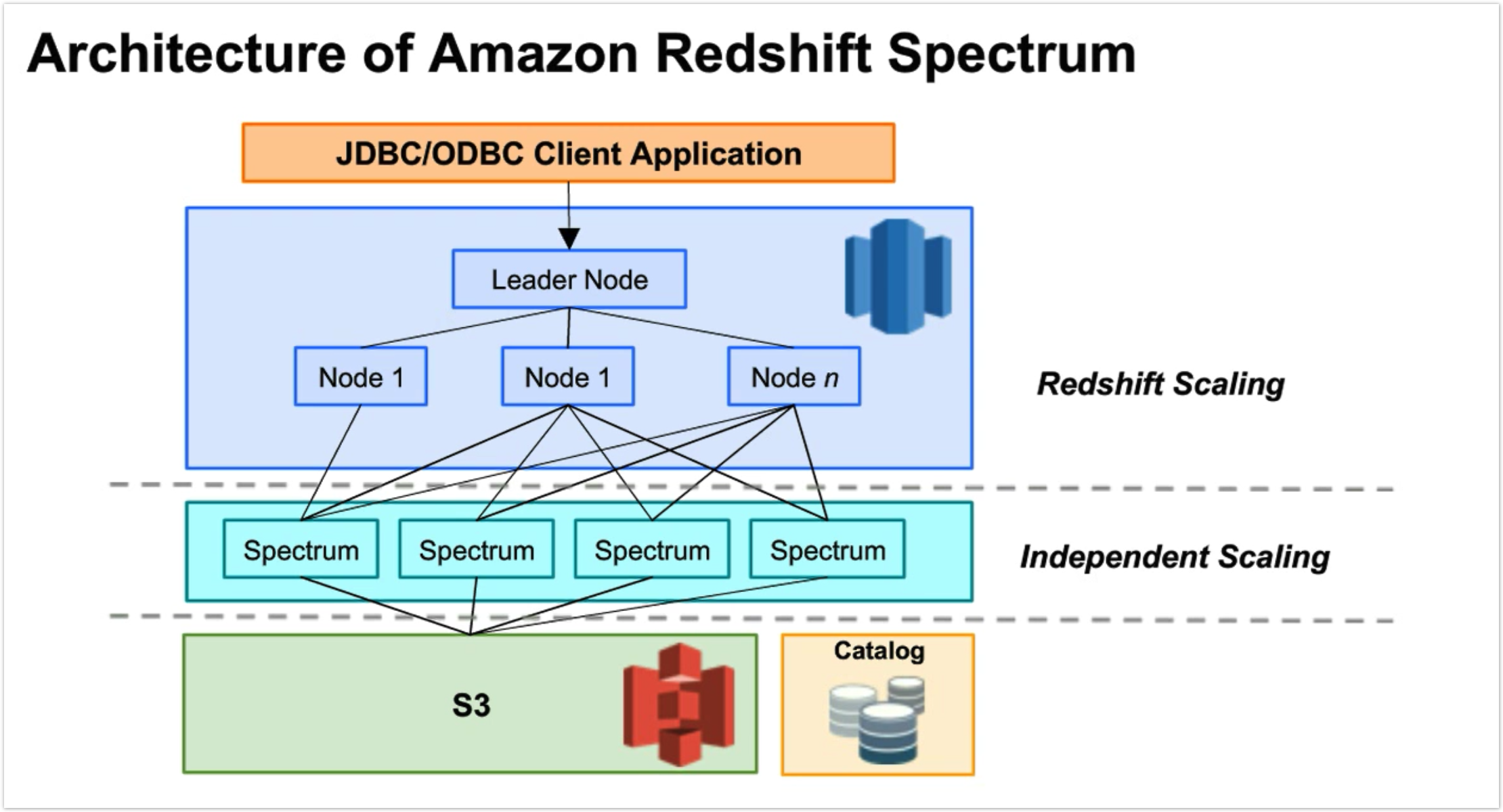
- Athena 와 유사하게 소스 데이터에 대해 직접 SQL 쿼리를 실행할 수 있음
- Athena와 Redshift는 공통 데이터 카탈로그와 공통 데이터 형식을 공유하므로 동일한 데이터 자산에 대해 Athena 및 Redshift Spectrum을 모두 사용할 수 있음.
데이터 정렬(Sorting Data) 와 Zone Maps
- slices 내에서 데이터는 sort key 를 기반으로 정렬됨
- 빈도 수가 높은 쿼리에서 sort key 로 사용할 것을 지정
- sort key 를 적용하면 Redshift 가 전체 블록을 읽는 것을 방지할 수 있음
백업 및 복구
S3 에 자동으로 증분 백업 데이터를 저장
- 시스템 스냅샷 유지 기간을 설정 가능 : 1~35일
- 사용자가 수동으로 스냅샷 생성 가능
- Streaming restore 기능을 지원하여, 클러스터가 만들어지면 즉시 쿼리 수행 가능
스냅샷에서 전체 클러스터 또는 특정 Table 복원 가능
- 노드의 자동 복구 기능 제공
- 자주 사용되는 데이터를 우선으로 복구함
업그레이드 및 확장
- 클러스터 가동 중에 resizing 실행 가능 (읽기 전용 모드로 전환됨)
- 백그라운드에서 새로운 클러스터를 프로비저닝함
- 노드 간에 병렬로 데이터를 복제함
- 소스 클러스터에 대한 비용만 발생됨
통합 쿼리
Amazon RDS 에 대한 통합 쿼리 지원
사용자 정의 함수 (UDF)
SQL 또는 Python 으로 UDF를 작성할 수 있음
Lambda UDF 지원
- Lambda 함수를 UDF 로 등록하고 Redshift SQL 쿼리에서 UDF 를 호출할 수 있음
- 함수 내에 강력한 작업 등을 포함하여 외부 서비스와 통합할 수 있음
- Lambda 가 지원하는 모든 언어 및 SELECT, UPDATE, INSERT, DELETE 등의 SQL 문과 스칼라 함수가 허용되는 SQL 문에서 Lambda UDF를 사용할 수 있음
캐싱
쿼리 및 결과를 캐싱함
스트리밍
기본 스트리밍 기능은 없으며, Kinesis Firehose 와 같은 AWS 서비스와 통합이 필요함
Google BigQuery
Google Cloud Platform 의 자체 데이터웨어 하우징 서비스임
- Google 에서 개발한 Dremel 이라는 쿼리 엔진을 사용함
- Borg 및 Colossus 와 같은 다른 Google Cloud 서비스를 활용할 수 있음
스토리지 형식
독자적인 ColumnIO 를 스토리지 형식으로 사용하고 Colossus 파일 시스템에 저장됩니다. 분산 컴퓨팅과 스토리지를 완전히 분리합니다.
- 압축 형식도 ColumnIO 열 형식으로 처리됨
데이터 접근 및 핸들링
ODBC/JDBC 외에도 GCP 콘솔 및 BigQuery API, CLI 를 통해 접근 가능함
통합 쿼리
Postgres 및 MySQL 데이터베이스 지원을 포함하는 CloudSQL 을 통해 통합 쿼리를 지원함
사용자 정의 함수 (UDF)
SQL 및 Java Script로 사용자 정의 함수 작성을 지원
- Google Cloud Storage의 외부 라이브러리를 포함할 수 있음
캐싱
쿼리를 캐시하고 인메모리 캐시를 제공하는 중간 캐시를 제공
데이터 소스
통합 쿼리를 통해 Cloud Storage, Google Drive, Bigtable, Cloud SQL등을 비롯한 일부 외부 데이터 소스에 대한 연결을 설정 할 수 있음
SnowFlake
SaaS(Software-as-a-Service) 모델로 제공되는 구조화된 데이터와 반 구조화된 데이터 모두를 지원하는 데이터웨어 하우스
- 기존 데이터베이스 또는 빅 데이터 소프트웨어 플랫폼(e.g. Hadoop)위에 구축되지 않음
- Snowflake는 클라우드 용으로 설계된 고유한 아키텍처가 존재하는 SQL 데이터베이스 엔진을 사용
Snowflake는 빠르고 사용자 친화적이며 기존 데이터웨어 하우스보다 더 많은 유연성을 제공함
- Snowflake는 Snowflake Elastic Data Warehouse의 형태로 클라우드 기반 데이터 스토리지 및 분석을 제공함
- 특정 클라우드(인프라)에 종속되지 않고, 어느 퍼블릭 클라우드에도 배포가 가능함
- Snowflake ETL을 사용하는 경우 Hadoop과 같은 기술을 사용하지 않고도 퍼블릭 클라우드 시스템을 활용할 수 있음
스토리지 형식
각 스토리지의 독점적인 Row 형식으로 제공하며, 메타 데이터 캐싱을 사용하여 PAX(하이브리드 컬럼 형식)로 저장
- 물리 데이터는 Amazon S3 등의 다른 클라우드 스토리지를 활용할 수 있음
컴퓨팅 형식
컴퓨팅 엔진은 클라우드(AWS, GCP, Azure)의 가상머신에서 실행되는 Intelligent Predicate Pushdown + Smart Caching이 포함된 독점 형태이며, C-Store, MonetDB에서 영감을 얻은 하이브리드 컬럼 시스템
데이터 접근 및 핸들링
솔루션의 유연성만큼 다양한 도구가 지원됨
- ODBC/JDBC
- Spark 플러그인 (spark-snowflake)
- Kafka
- Python/Node.js/Go/.Net 드라이버
- SnowSQL
- Snowsight
통합 쿼리
현재 통합 쿼리를 지원하지 않음
캐싱
콜드 데이터 스토리지와 분리된 중간 스토리지에 Hot/Warm 쿼리 캐시를 제공
스트리밍
snowpipe를 통해 Amazon S3, Google Cloud Storage, Azure Blob Storage에서 마이크로 배치를 할 수 있지만, 기본 스트리밍 기능은 없음
데이터 소스
최상의 성능을 위해서 Snowflake 내에 데이터가 있는 것이 이상적임
하지만 Snowflake 내로 데이터를 가져오는 것을 강요하지 않으며, 주요 클라우드 (Amazon S3, Google Cloud Storage, Azure Blog Storage)의 객체 스토리지에 연결할 수 있는 외부 테이블 기능을 제공함
답글 남기기