개념
data lake
데이터 레이크는 대규모의 다양한 원시 데이터 세트를 기본 형식으로 저장하는 데이터 리포지토리 유형
데이터 레이크를 사용하면 정제되지 않은 데이터를 볼 수 있으며, 데이터에 대해 전체적인 대규모 리포지토리를 엔터프라이즈 환경에서 데이터 관리 전략으로 보편화할 수 있음
“데이터 레이크”라는 용어는 Pentaho의 CTO(최고 기술 책임자)인 James Dixon이 처음으로 소개함.
이러한 유형의 데이터 리포지토리를 레이크라고 부르는 이유는 필터링되거나 패키지화되지 않은 수역과 같은 자연 상태의 데이터 풀을 저장하기 때문이다. 데이터는 여러 소스에서 레이크로 흐르며 원래 형식으로 저장됨
- 데이터 종류의 무한함
- 모든 유형의 정형 데이터와 다양한 비정형 데이터를 저장
- 사전 정의 및 분석되지 않음
- 원시 데이터를 저장할 뿐이며, 원시 데이터에 대한 이해와 인사이트가 향상될 때 데이터를 정제함
- 데이터 조회 방법에 제한이 없음
- 다양한 도구를 사용할 수 있음
- 하나로 통합된 저장소
- 조직 전체가 하나의 통합된 뷰로 데이터에 접근함
원시 데이터
원시 데이터는 특정 목적을 위해 처리되지 않은 데이터를 말함. 데이터 레이크에 있는 데이터는 쿼리되기 전까지는 정의되지 않음
거버넌스
데이터 레이크에 있는 데이터는 분석을 위해 필요할 때 변환되며, 이러한 경우 스키마가 적용되어 데이터 분석이 가능해짐.
이는 “읽기 스키마(schema on read)”라고 불리는데, 데이터가 사용 준비 상태가 될 때까지 원시 상태로 보관되기 때문이다.
해당 데이터를 사용하고 이에 액세스할 수 있도록 거버넌스를 통해 데이터 레이크를 지속적으로 유지 관리해야 하며, 나중에 액세스할 수 있도록 데이터를 데이터 레이크에 보관하는 경우 메타데이터로 태그를 지정해야 함.
data swamp (데이터 늪)
data lake 구성에 실패하면 데이터를 제대로 활용할 수 없는 상태가 되며 이를 data swamp 라고 함
data lake 를 적절히 설계하고 그 안의 데이터를 효율적으로 관리하지 못함
- 사용자 중심의 데이터와 메타데이터를 관리하는 플랫폼이 필요
- Hadoop 은 복잡한 시스템이며, 이 에코시스템을 직접 구축하는 것은 쉬운 작업이 아님
- 우선 이상적인 시스템보다는 필요한 분석을 위한 기능을 구현하는 것을 목표로 함
data lake 를 ad-hoc 탐색, 분석으로만 사용함
- 해결해야 하는 다양한 비즈니스 문제를 도출해야 함
손에 넣을 수 있는 모든 정보를 수집한 다음, 나중에 어떤 분석을 시도할지 결정하는 것
- 초기에는 적은 데이터, 목표에 따른 데이터를 수집해야 함
- 품질이 좋고, 이해할 수 있는 데이터 세트를 수집하는 것이 유리함
데이터 준비 (data preparation)
데이터 준비는 분석 또는 기타 평가 목적으로 데이터를 구체화하기 위해 데이터를 정리, 리포맷 및 모델링하는 작업
일반적으로 Define, Identify, Transform, Model, Load, Verify 와 같은 단계가 포함됨
해당 작업에 해당하는 용어는 몇가지가 있지만 대표적으로 ETL, data wrangling, data mining 가 있음
데이터 준비는 엔드유저에게 비즈니스 문제에 대한 답을 직관적이고 쉽게 제시할 수 있으며, BI 솔루션 성능에 큰 영향을 미칠 수 있음
- 분석 및 시각화를 위한 데이터는 깨끗하고 오류가 없어야함
- 이미 분석을 위해 데이터가 전송된 후에는 발견 및 수정이 어려워짐
클라우드 마이그레이션 프로세스를 위해 필수적임
- 클라우드에서 데이터 준비를 수행하면 인적 리소스를 절감할 수 있고, 모든 부서에서 액세스할 수 있어 협업이 쉬워짐
- 클라우드 스토리지의 유연성은 비즈니스(데이터)가 성장함에 따른 데이터 준비 작업에 대한 스케일업도 용이하게 해준다
- 새로운 기술이나 트렌드를 도입하기 쉬워짐
조직의 데이터에 대한 좋은 관행(문화) 이 될 수 있음
- 데이터 거버넌스를 세워 기업이 안전하고 기준을 준수하는 데 도움을 줌
- 데이터의 특징 및 출처, 이력 등을 추적할 수 있음
- 조직이 기업 환경의 문제를 인식할 수 있고, 개선된 분석 문제를 갖게 됨
- 데이터 처리 체계를 세워, 여러 작업자가 동일한 툴을 사용하여 처리할 수 있음
ETL
원시 데이터 혹은 애플리케이션 데이터를 추출하여 정제한 후에 데이터 웨어하우스에 적재하는 모든 과정을 말함
일반적으로 데이터 정제(변환)에는 필터링, 정렬, 집계, 데이터 조인, 데이터 정리, 중복 제거 및 유효성 검사 등의 다양한 작업이 포함됨
- Extract : 하나 또는 여럿 데이터 소스로부터 데이터 추출
- Transform : 데이터 클렌징, 형식 변환 및 표준화, 통합 또는 다수 애플리케이션에 내장된 비즈니스룰 적용 등
- Load : 정제 완료된 데이터를 데이터 웨어하우스 시스템에 적재
data wrangling
복잡하고 큰 원시 데이터를 분석하기 좋은 데이터로 변환하여 데이터 사용성을 높이는 작업
데이터 랭글링은 총 5단계로 분류됨
- Gather : 데이터를 얻는 단계
- Assess : 데이터의 상태를 판단하는 단계
- Clean : 데이터를 정제하는 단계
- Reassess and Iterate : 데이터가 잘 정제되었는지 판단하고 반복하는 단계
- Store : 데이터를 저장하는 단계
ETL 과 데이터 랭글링의 차이
ETL 과 데이터 랭글링은 유사하게 사용되지만, 동일한 것을 지칭하는 용어가 아님
| ETL | 데이터 랭글링 |
| 엔드유저 중심.
특정 시스템에서 원하는 데이터를 추출, 변형 및 탑재 |
데이터 랭글링 과정은 관리자, 영업 담당자 및 기업 분석가 중심으로 이뤄짐 |
| 대용량 데이터 처리를 위해 구조화 및 비구조화 데이터를 다루는 작업 | 복잡하거나 용량이 큰 데이터를 분석할 수 있도록 정제 및 최적화를 적용 |
data mining
대규모 데이터 세트에서 숨겨진 패턴과 관계를 찾는 작업
데이터 랭글링은 이보다 상위 집합이며 의사 결정을 위한 정리, 변환, 통합 등의 다른 작업들을 포함함
데이터 파티셔닝 (data partitioning)
효율적인 쿼리를 위해서는 데이터의 적절한 분할이 필수다.
데이터 세트를 분석 및 활용 목표에 따른 효율적인 방식으로 분할할 필요가 있음
- 예시 1
- 고양이나 축구를 좋아하며 서울에 거주하는 고객의 구매 행동을 예측하는 기계 학습 모델을 개발한다고 가정하면, 고객 데이터 세트가 도시, 동물, 스포츠로 분할된 경우 데이터 과학자는 필요한 데이터를 어디서 찾을 수 있는지 정확히 알 수 있음
- 반면에 이 데이터 세트가 성별로 분할된 경우 관련 데이터를 찾기 위해 고객 데이터 세트의 모든 행을 분석해야 함
- 예시 2
- 상품 가격을 업데이트하기 위한 데이터베이스가 있고, 어제 가격이 업데이트된 상품을 모니터링하기위한 데이터 세트가 생성되었다고 가정하면, 여기에서 분명한 선택은 update_date로 입력 데이터 세트를 분할하는 것임.
- 몇달 후에 각 상품의 최종 가격을 알기 위해 잡을 새로 생성한다면, 데이터 세트가 이미 update_date 로 분할되어 있기 때문에 대부분의 데이터를 쿼리해야 함. 만일 article-id 로 분할했다면 각 article-id 의 최신 행을 쿼리하면 빠르게 완료할 수 있는 작업임
- 미래에는 매우 다른 방식으로 데이터를 쿼리해야 하는 상황이 발생할 수 있으므로, 데이터 파티셔닝 전략은 유연성있게 수시로 재검토 되어야 함
다만 데이터 파티셔닝에는 이점만 있는 것이 아니며, 리스크도 분명 존재함
- 파티셔닝이 많을수록 생성되는 파일 수는 많아지며, Hadoop 이나 spark 와 같은 데이터 처리 시스템의 성능 저하의 요인이 될 수 있음.
- 데이터 통계적인 부분에서도 단일 파티션일 경우가 더 안전하게 데이터를 쿼리할 수 있음
data lake vs data warehouse
데이터 레이크와 데이터 웨어 하우스는 종종 혼동되지만, 이 둘은 동일하지 않으며 그 목적도 다르다.
둘 다 빅데이터를 위한 데이터 스토리지 리포지토리라는 것만이 유일한 유사점임.
|
data lake |
data warehouse |
|
| 저장 방식 | 비정형 원시 데이터 (구조화되지 않음) | 분석 가능한 형태의 구조화된 데이터 모델 |
| 소스 | IoT 장치, 웹사이트, 모바일 앱, SNS, 애플리케이션 | 트랜잭션 시스템(OLTP), 운영 데이터베이스, LOB 애플리케이션 |
| 목적 | 미래 사용을 염두에 두며, 보유를 목적으로 하기도 함 (schema-on-read) | 주제 지향성을 가지며, 사전에 목적이 정의됨 (schema-on-write) |
| 수집 속도 | 즉시 수집 가능 (사후에 ETL 작업 진행) | 수집까지 많은 시간이 소요 (사전에 ETL 작업 진행) |
| 데이터 분석 | 고급 필터 및 분석 기술이 필요. 분석 도구에 제한이 없음. | 데이터 구조가 사전 정의되어 있음. 제한적인 분석 도구를 사용. |
| 유연성 | 데이터의 업데이트가 빈번하고 빠름 | 구조 변경이 거의 없으며, 입력된 데이터는 업데이트 되지 않음 |
| 보안(폐쇄성) | 비교적 취약함(오픈 소스 기술 사용, 접근성이 높음) | 비교적 견고함(상용 소스 사용, 접근이 제한적임) |
| 이용자 | 데이터 과학자 및 분석가 (전문 지식 필요) | 비즈니스 애널리스트와 비즈니스 담당자들에게 적합 (비 IT 인력) |
| 용도 | 기계 학습, 예측 분석, 데이터 검색 및 프로파일링 | 일괄 보고, BI 및 시각화 |
| 비용 / 성능 | 비용이 저렴함 / 느림 | 비용이 큼 / 빠름 |
Elasticsearch vs Hadoop
|
Elasticsearch |
Hadoop |
|
| 특징 | RESTful 기반의 분산형(클러스터) 구조의 오픈소스 검색 엔진 | 안정적이고 확장가능한 분산 컴퓨팅 오픈 소스 소프트웨어 |
| 용도 | 검색엔진, 웹 및 로그 분석 | 빅데이터 분석 |
| 동작 방식 | REST 아키텍처 기반의 HTTP 통신으로 CRUD 작업을 수행하는 API 엔드포인트를 제공함 | 마스터-슬레이브 아키텍처 내에서 HDFS 및 MapReduce 프로그래밍을 사용하여 데이터를저장 및 처리함 |
| 언어 형식 | JSON 기반의 풀쿼리 DSL 제공 | 대규모 데이터 클러스터 처리를 위한 MapReduce 프로그래밍 모델을 사용 |
| 활용 | 풀텍스트 검색 엔진, 분석 프레임워크 | 데이터를 저장하고, 클러스터에서 애플리케이션을 실행하는 도구 |
| 동작 환경 | Java VM 이 동작 가능한 운영체제 | Linux, Unix, Windows |
| 쿼리 | SQL 과 유사한 쿼리 언어 | Hive 로 쿼리를 처리함 |
| 차이점 | 검색 상단에서 웹 및 로그 분석에 용이함 | 메모리 제약이 없는 분산 환경을 구축하여, Rich API 를 위한 데이터 변환 및 준비를 할 수 있음 |
data lake 의 구축 및 관리
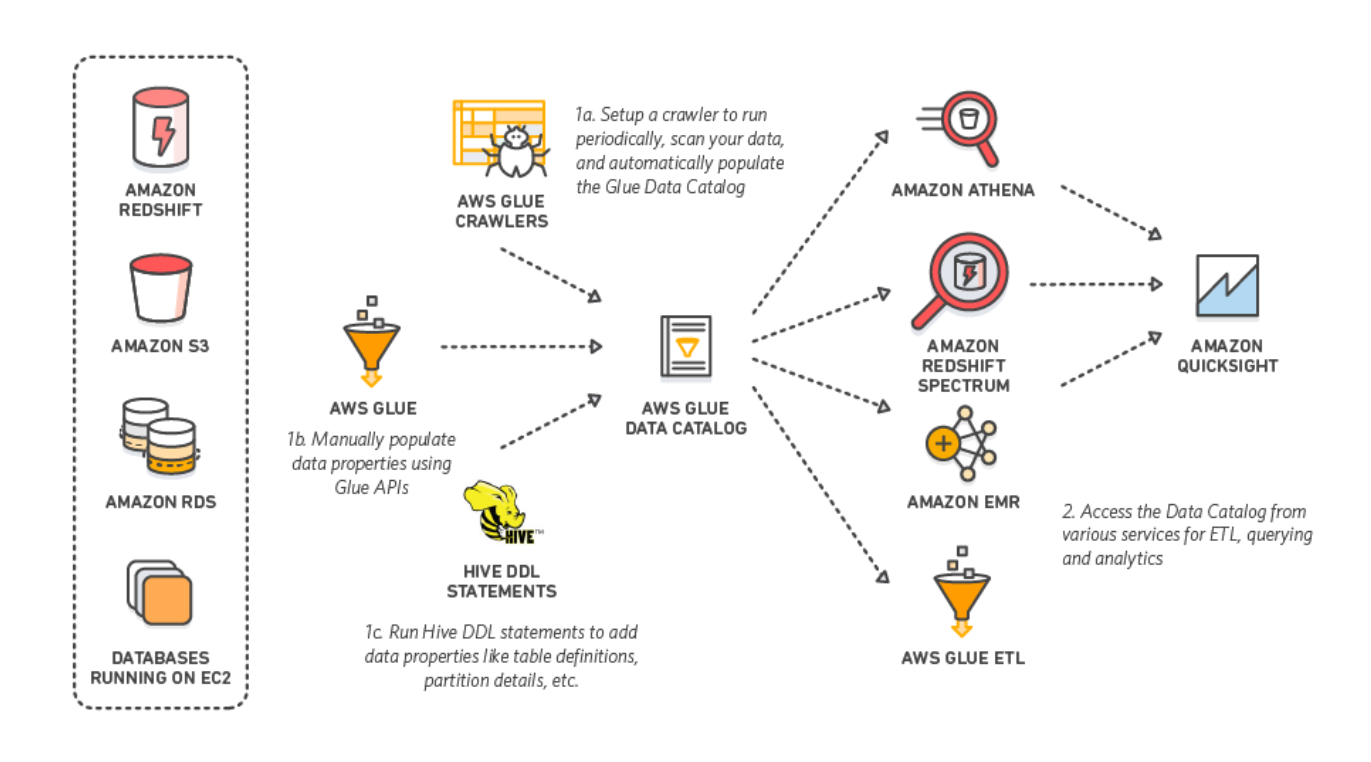
AWS data lake 의 워크플로우
https://docs.aws.amazon.com/glue/latest/dg/populate-data-catalog.html
AWS data catalog 생성
| 원시 데이터 저장 / 거버넌스 | 수집 및 분석 | 활용 | |
| Storage | Data Catalog | Analytics (Data Processing) | BI & ML |
| S3 (메인 스토리지) | Glue Crawler | Glue ETL (데이터 수집 및 변환) | QuickSight |
| RedShift (Data Warehouse) | Glue Data Catalog | EMR (빅데이터 처리) | Sagemaker |
| RDS (RDBMS) | Hive Metastore | Athena (대화식 분석) | Rekognition |
| DynamoDB (NoSQL) | Athena | Kinesis Firehose (실시간 수집 및 분석) | Forecast |
| Elasticsearch (데이터 검색, 인프라 분석) | |||
Amazon S3
AWS 에서의 data lake 구축은 S3 가 핵심이 된다. S3는 사실상 무제한 확장성으로 인해 데이터 레이크에 최적의 기반을 제공함.
- 내구성, 가용성, 확장성 충족
- 비용 효율화를 위한 기능 제공
- 여러 AWS 서비스 및 분석툴과 통합 가능
- 객체 레벨 컨트롤
- 최고의 보안성, 컴플라이언스, 감사
AWS GLUE
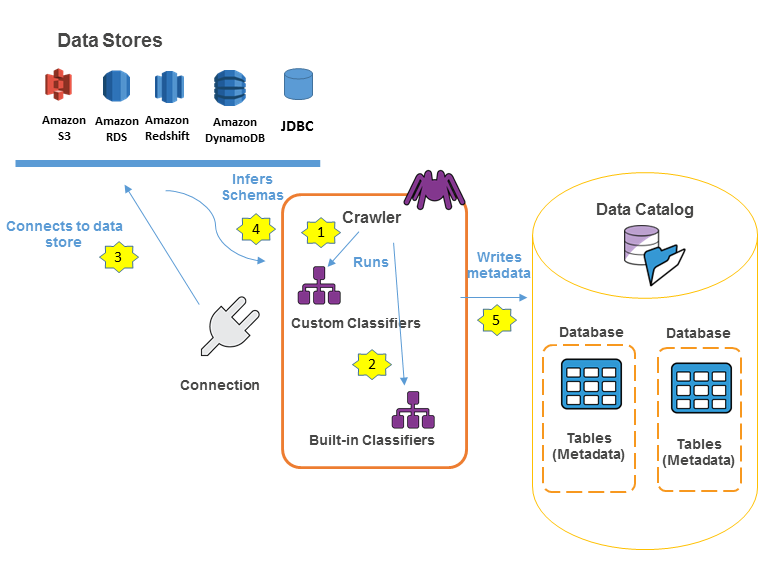
https://docs.aws.amazon.com/ko_kr/glue/latest/dg/components-key-concepts.html
AWS GLUE 의 워크플로우
GLUE 는 S3 기반 data lake 를 구축함에 있어 거버넌스(데이터 카탈로그), ETL 를 수행할 수 있는 필수 구성 요소임
- 크롤러를 통해 AWS Glue 데이터 카탈로그에 메타데이터 테이블 정의를 생성함
- ETL 작업을 정의하는 데 필요한 기타 메타데이터도 생성됨
- AWS 콘솔이나 API 를 통해 스크립트를 실행하여 데이터 변환(ETL)을 수행함
- 작업 방식은 온디맨드, 스케쥴 혹은 이벤트 기반의 트리거를 통해 작업을 시작할 수 있음
- Apache Spark 로 구성된 가상 환경에서 작업이 진행됨
데이터 카탈로그
데이터 카탈로그는 데이터 레이크의 S3 버킷에 저장된 모든 자산의 쿼리 가능한 인터페이스를 제공함.
데이터 카탈로그는 데이터 레이크의 내용에 대한 단일 진실 소스(single source of truth, SSOT)를 제공하도록 설계됨.
GLUE 는 JSON, CSV, Parquet 등의 형식을 classifiers 를 통해 데이터 카탈로그를 구성할 수 있음. 또한 Hive 호환 메타스토어 형식인 HCatalog 를 사용하므로, 타사 분석 도구에서도 사용할 수 있음
Classifier
데이터의 스키마를 결정함.
AWS Glue 는 CSV, JSON, AVRO, XML 등과 같은 일반적인 파일 형식에 대한 분류자를 제공하며, grok 패턴이나 XML 행 태그를 통한 자체 분류자도 작성할 수 있음
Crawler
데이터 스토어에 연결하여 Classifier 를 통해 데이터의 스키마를 결정한 다음, AWS Glue 데이터 카탈로그에 메타데이터 테이블을 생성하는 프로그램임
스트리밍
Glue 를 통해 스트리밍 데이터에 대한 ETL 작업을 수행할 수 있음
AWS Glue 스트리밍 ETL은 Apache Spark Structured Streaming 엔진을 기반으로 하며 Amazon Kinesis 데이터 스트림, Apache Kafka 및 Amazon MSK 에서 스트림을 수집할 수 있음
스트리밍 ETL은 스트리밍 데이터를 정리하고 변환하여 Amazon S3 또는 JDBC 데이터 스토어에 로드할 수 있으며, AWS Glue 에서 스트리밍 ETL을 사용하여 IoT 스트림, 클릭스트림 및 네트워크 로그와 같은 이벤트 데이터를 처리함
스트리밍 데이터 원본의 스키마를 알고 있는 경우 데이터 카탈로그 테이블에서 해당 스키마를 지정할 수 있고, 그렇지 않은 경우 스트리밍 ETL 작업에서 스키마 감지를 사용하도록 설정할 수 있다. 그리고 다음에 들어오는 데이터에서 스키마를 자동으로 결정함.
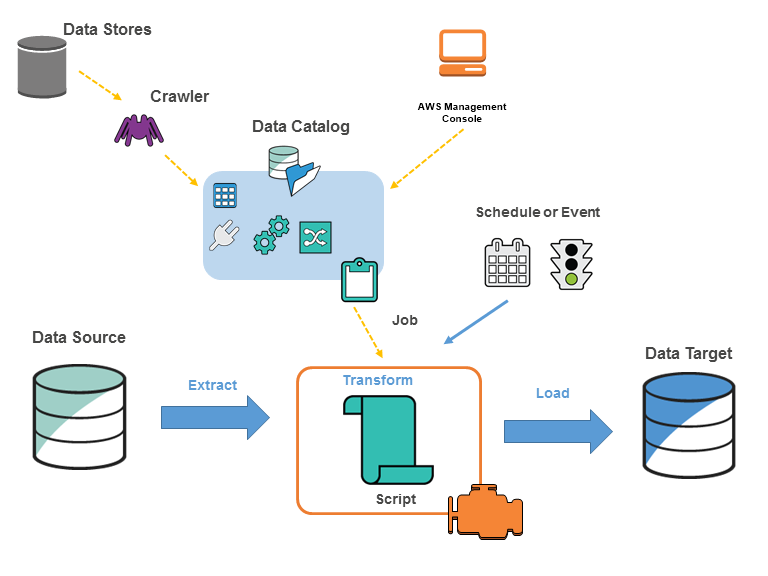
AWS Glue Job
AWS Glue Jobs 시스템은 ETL 워크플로우를 오케스트레이션하기 위한 관리형 인프라를 제공함.
AWS Glub 작업의 스크립트 실행을 자동화할 수 있으며, 일정 주기 혹은 새로운 데이터가 저장되는 이벤트 등에 의해 트리거를 실행시킬 수 있음
Apache Parquet
Parquet는 데이터 처리 프레임워크, 데이터 모델 또는 프로그래밍 언어에 관계없이 대량의 데이터를 쿼리하도록 설계된 압축 저장소 파일 형식이다.
CSV, JSON 또는 TXT 형식과 같은 일반적인 원시 데이터 로그 형식과 비교하여 Parquet는 필요한 스토리지 공간을 줄이고 쿼리 성능을 크게 개선하며 검색된 데이터 양에 따라 비용을 청구하는 AWS 서비스의 쿼리 비용을 크게 절감할 수 있음.
- Parquet을 사용하면 공간이 최대 87% 절약됨
- 대표 Athena 쿼리의 쿼리 시간은 Parquet의 경우 최대 34배 더 빠르며, Athena 쿼리의 검색된 데이터 양은 최대 99% 더 적음
- Athena 쿼리를 실행하는 데 드는 비용은 최대 99.7% 낮음
S3 기반의 데이터 레이크에서 Parquet 으로 데이터를 변환하는 방법은 2가지가 지원됨.
- S3의 원시 데이터를 소스로 Hive가 설치된 EMR 클러스터를 생성하고, 이 데이터를 Hive 테이블로 변환한 다음, 이러한 Hive 테이블을 Parquet 형식으로 Amazon S3에 다시 쓰는 방법
- PySpark 에서 코드를 실행하여 변환
- GLUE ETL 을 사용하여 변환 작업을 자동화
- 데이터 레이크의 S3 버킷에 있는 원시 데이터를 자동으로 수집하고, 데이터 형식을 식별한 다음, 데이터 흐름에 시간을 할애하지 않도록 스키마와 변환을 제안함
Athena
표준 SQL을 사용하여 Amazon S3에서 데이터를 쉽게 분석할 수 있는 대화형 쿼리 서비스이다.
Athena는 서버리스이며, 설정하거나 관리할 인프라가 없으며 사용자는 쿼리를 실행하여 검색된 데이터 자산 볼륨에만 비용을 지불함. 그리고 자동으로 실행되는 쿼리를 병렬로 확장하므로 대규모 데이터 세트와 복잡한 쿼리에서도 결과가 빠름
Athena 에는 데이터 소스 연결 시에 데이터 카탈로그로서 Glue 나 Hive 메타스토어를 사용할 수 있음
Athena는 Amazon QuickSight와 통합되어 쉽게 시각화할 수 있음. 또한 이러한 툴을 JDBC 드라이버로 Athena에 연결하여 타사 보고 및 비즈니스 인텔리전스 툴과 함께 사용할 수 있음
그리고 Athena 는 작업 그룹을 사용하여 팀, 애플리케이션 등의 워크로드를 분리하여 쿼리 작업을 시행할 수 있음. 각 작업 그룹은 해당 쿼리에 대해서만 저장하고, 히스토리를 남기며, 작업 한도를 설정할 수 있고, 또한 CloudWatch 지표 및 IAM 을 통한 권한 부여도 작업 그룹 단위로 진행할 수 있음
Redshift Spectrum
Redshift는 Amazon S3의 데이터 자산과 함께 사용할 수 있는 대규모의 관리형 데이터 웨어하우스 서비스이다.
Redshift 에서 쿼리를 실행하려면 먼저 데이터 자산을 Amazon Redshift에 로드해야 하지만 Redshift Spectrum을 사용하면 Amazon S3 기반 데이터 레이크에 최대 엑사바이트 저장되는 방대한 양의 데이터에 대해 직접 Amazon Redshift SQL 쿼리를 실행할 수 있음.
Redshift Spectrum은 정교한 쿼리 최적화를 적용하여 수천 개의 노드 간에 프로세싱을 확장하므로 대용량 데이터 세트와 복잡한 쿼리에서도 결과가 빠름
Athena와 Redshift는 공통 데이터 카탈로그와 공통 데이터 형식을 공유하므로 동일한 데이터 자산에 대해 Athena 및 Redshift Spectrum을 모두 사용할 수 있음.
일반적으로 애드혹 데이터 검색 및 SQL 쿼리에 Athena를 사용한 다음 Redshift Spectrum을 사용하여 많은 수의 데이터 레이크 사용자가 동시 BI 및 보고 워크로드를 실행하고자 하는 보다 복잡한 쿼리 및 시나리오를 수행할 수 있음
Kinesis
Kinesis Firehose는 Amazon S3에 실시간 스트리밍 데이터를 직접 전송하기 위해 사용한다.
Kinesis Firehose는 스트리밍 데이터의 볼륨 및 처리량에 맞게 자동으로 확장되는 완전관리형 AWS 서비스이다.
Kinesis Firehose 의 기능에는 압축, 암호화, 데이터 일괄 처리 및 Lambda 기능이 있다.
Kinesis Firehose는 Amazon S3에 저장하기 전에 데이터를 압축할 수 있다. 현재 GZIP, ZIP 및 SNAPPY 압축 형식을 지원하며, GZIP는 Amazon Athena, Amazon EMR 및 Amazon Redshift에서 사용할 수 있으므로 선호되는 형식이다. 그리고 Kinesis Firehose 암호화는 AWS KMS 를 통한 Amazon S3 서버측 암호화를 지원함.
또한 Kinesis Firehose는 여러 개의 들어오는 레코드를 연결하여 하나의 S3 객체로 Amazon S3에 전달할 수 있는데, 이는 S3 의 트랜잭션 비용 및 횟수를 줄일 수 있음
마지막으로 Kinesis Firehose는 Lambda 기능을 호출하여 들어오는 소스 데이터를 변환하여 Amazon S3에 전송할 수 있음. 일반적으로 Apache Log 및 Syslog 형식을 표준 JSON 및/또는 CSV 형식으로 변환하는 기능이 있으며, 이를 Amazon Athena를 사용하여 JSON 및 CSV 형식을 직접 쿼리할 수 있다.
EMR
EMR은 오픈 소스 프레임워크인 Apache Hadoop을 사용하여 탄력적으로 크기가 조정 가능한 EC2 인스턴스 클러스터 전체에 데이터 및 처리를 배포하고 Hive, Pig, Spark 및 HBase와 같은 모든 일반적인 Hadoop 도구를 사용할 수 있다.
EMR은 Hadoop 클러스터의 인프라 및 소프트웨어 프로비저닝, 관리 및 유지 보수와 관련된 모든 작업을 수행하며 Amazon S3와 직접 통합됨
Amazon EMR을 사용하면 무한정 가동 상태를 유지하는 영구 클러스터를 실행하거나 분석이 완료된 후 종료되는 임시 클러스터 모두 대응할 수 있으며, 클러스터가 가동된 시간 만큼만 비용을 지불함
Amazon EMR은 EC2 인스턴스를 통해 구축되며, 범용, 컴퓨팅, 메모리 및 스토리지 I/O 등의 다양한 유형과 가격 옵션(온디맨드, 예약 및 스폿)을 지원한다.
Elasticsearch
자산 및 메타데이터, 데이터 분류에 대한 검색 엔진으로 활용 가능함
운영 인프라의 모니터링을 위한 로그 분석 시스템으로도 활용할 수 있음
Hadoop(EMR) 와 유사한 클러스터링(분산) 구조, 검색 기능(인덱싱) 등의 기능을 지원하지만, 아래와 같은 차이점을 가짐
- 샤드(노드) 확장에 대한 유연성이 떨어짐 (인덱스를 생성할 때, 미리 데이터의 크기를 추측해야 함)
- 엄연히 말해 스키마가 있는 구조임 (ES 에 맞는 json 형식으로 변환해야 최적의 효율을 얻을 수 있음)
- 버퍼 제한이 100MB 이므로, 대용량 업로드 시에 많은 오류를 동반함
- 아직 ES 의 에코시스템은 Hadoop 에 비해 분석 기능의 지원이 부족함
물론 ES 는 Hadoop 의 기능을 대체할 수는 없지만, ES 만의 인덱싱 기능, 웹 및 로그 분석 기능을 활용하여 data lake 시스템에 많은 도움을 줄 수 있음
AWS Lake Formation
data lake 를 손쉽게 설정할 수 있도록 지원하는 서비스
data lake 를 설정하고 관리하기 위해서는 복잡하고 시간이 소요되는 작업이 필요함.
- 다양한 소스로부터 데이터를 로딩
- 데이터 흐름 모니터링
- 데이터 파티셔닝
- 암호화 설정 및 키 관리
- 액세스 제어 설정
- 변환 작업 정의 및 운영 모니터링, 중복 데이터 제거
- 컬럼 기반 형식으로 데이터 재구성
- 링크된 레코드 매칭
- 액세스 감사(audit)
Lake Formation 은 이러한 data lake 구축 관련 작업을 관리할 수 있는 콘솔 및 편의 기능을 제공함
데이터 로드
S3 버킷을 등록하여 데이터를 로드할 수 있음
데이터베이스를 자동 생성해주며, 이 데이터베이스는 Glue Data Catalog 로 등록되며, 메타데이터가 여기에 보관됨
권한 관리
권한 관리는 data lake 구축에서 가장 복잡한 작업 중 하나임.
data lake 에는 엄청난 양의 데이터가 포함되며, 이는 서로 다른 구조화, 반구조화, 비구조화 형태로 혼재되어 있음
Lake Formation 은 IAM 정책을 보강하는 새로운 grant/revoke 권한을 통해 data lake 에 저장된 데이터에 안전하고 세분화된 방식으로 액세스할 수 있음
IAM 사용자, 역할, 그룹 및 Active Directory 연동 사용자의 데이터베이스, 테이블에 대한 액세스 권한을 관리할 수 있음
또한 특정 컬럼, 작업 권한에 대해서도 허용하거나 차단할 수 있음
제한된 사용자(역할)는 테이블을 쿼리할 때 권한이 부여된 열에 대해서만 쿼리 결과를 볼 수 있음
블루프린트
블루프린트를 사용하여 데이터 수집을 간소화할 수 있음
AWS Glue 에서 사용할 수 있는 워크플로, 크롤러 및 작업을 생성할 수 있음
- 워크플로는 트리거, 크롤러, 작업 같은 Glue 엔터티 간 종속성을 구축하여 워크로드를 오케스트레이션함
- 워크플로에 있는 여러 노드 상태를 콘솔에서 시각적으로 추적하고 모니터링할 수 있음
데이터베이스 블루프린트를 사용하면 운영 데이터베이스에 적재된 데이터를 data lake 로 로드할 수 있음
로그 파일 블루프린트를 사용하면 ELB, ALB 및 CloudTrail 에 사용되는 로깅 형식을 간편하게 수집할 수 있음
답글 남기기