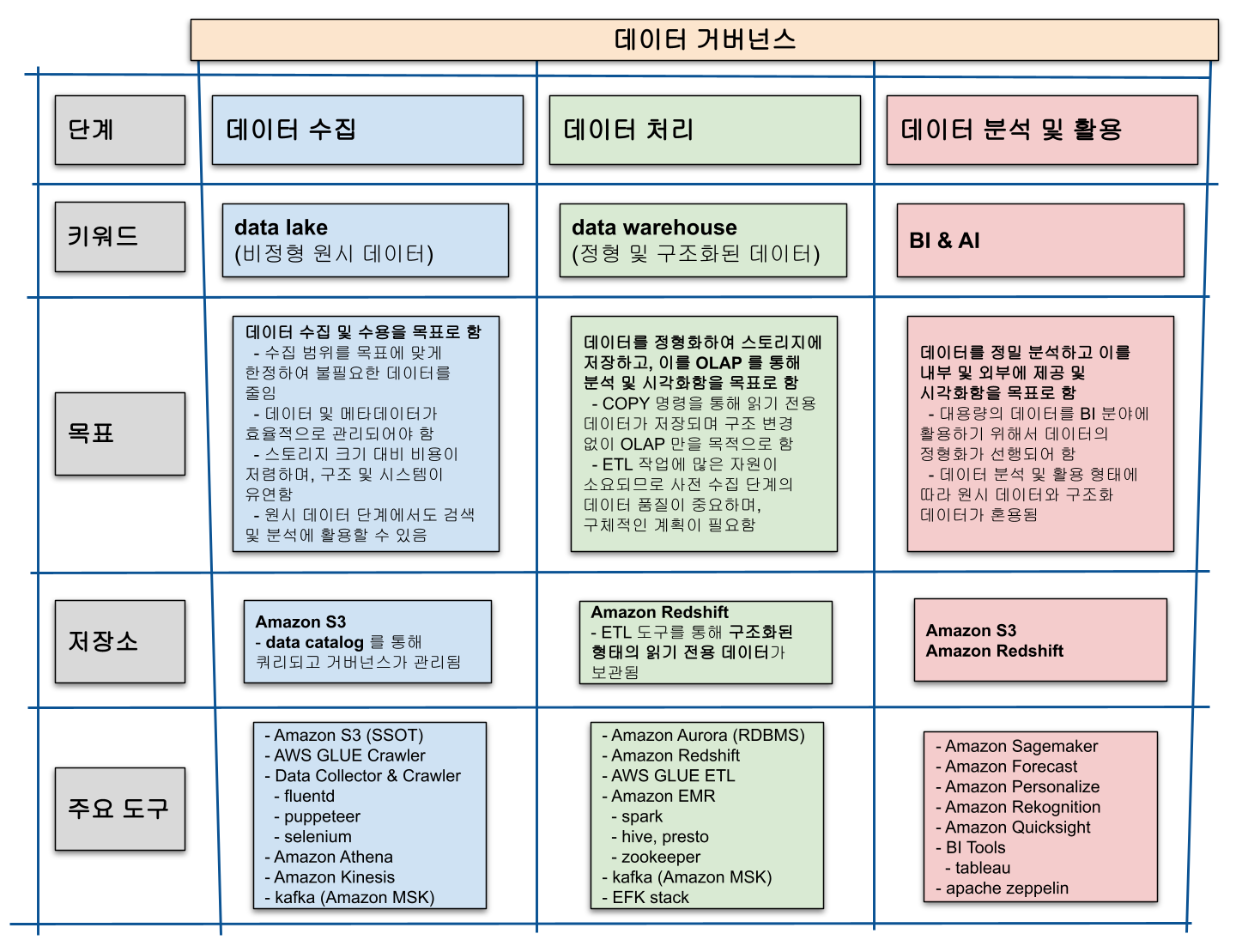
데이터 거버넌스
데이터 거버넌스의 개념
데이터 거버넌스란 데이터의 보안, 개인정보 보호, 정확성, 가용성, 사용성을 보장하기 위해 수행하는 모든 작업을 가리킴. 여기에는 사람이 취해야 하는 조치, 따라야 하는 프로세스, 데이터의 전체 수명 주기 동안 이를 지원하는 기술이 포함됨
- 데이터 거버넌스는 데이터 수집, 저장, 처리, 폐기 방법에 적용되는 내부 표준(데이터 정책)을 설정하는 것을 의미함
- 이를 통해 누가 어떤 종류의 데이터에 액세스할 수 있고, 어떤 종류의 데이터가 거버넌스 대상인지를 제어함.
- 업계 협회, 정부 기관, 기타 이해 관계자가 설정한 외부 표준을 준수하는 것도 데이터 거버넌스에 포함됨
데이터 거버넌스는 고정된 의미를 갖는 것이 아닌, 일정 개념에 대한 정의이므로, 기업 경영에서 데이터의 중요성이 커지면서 그 개념도 발전하여 왔다.
데이터 거버넌스의 필요성
- 데이터 생산자, 처리자, 사용자가 다르며 서로 어떤 데이터가 생산되고 처리되었는지 알지 못함
- 하나의 데이터로 서로 다른 사용 목적을 모두 충족시키기 어려움
- 기업이 사용하는 데이터 정의와 외부 공급자가 개발한 데이터 정의는 서로 다름
- 데이터 규제가 점점 더 다양하게 적용되고 있으며, 데이터 규제를 따르지 않으면 기업은 제재를 받을 수 있음.
- 데이터의 올바른 사용을 위해서는 데이터 컨텍스트를 기록하는 메타데이터가 필요하다.
- 데이터와 데이터 활용자(활용처)는 계속 늘어난다. 이에 따라 한정된 인원으로 데이터를 관리하기 위해서는 효율적인 관리 체계가 필요함
데이터 거버넌스의 이점
- 더 현명하고 시기적절한 의사 결정
- 데이터 컨텍스트를 기록하여 데이터 오용을 방지함
- 외부 데이터 확보 및 융합이 쉬워짐
- 비용 관리 개선
- 데이터를 효율적으로 관리하고, 중복 데이터를 제거할 수 있음
- 규정 준수 강화
- 컴플라이언스 리스크에 대처
- 고객 및 공급업체의 신뢰도 향상
- 보다 쉬운 위험 관리
- 적절한 권한 관리 및 민감 정보, 보안 침해를 보호
- 더 많은 직원이 더 많은 데이터에 액세스할 수 있도록 함
- 세부적인 권한 부여
- 데이터에 대한 이해와 신뢰를 높여, 데이터 활용을 확산시킴
데이터 거버넌스의 용도
데이터 책임성
- 데이터 관리자에게 적절한 사용을 보장하는 프로세스와 데이터 자체에 대한 책임성 및 의무를 부여하는 것을 의미함
데이터 품질
- 데이터 사용성을 확인하기 위한 모든 활동 또는 기술을 의미함
- 정확성, 완전성, 일관성, 시의성, 타당성, 고유성
데이터 관리
- 수집 및 저장, 사용, 감독에 이르기까지 데이터를 기업 자산으로서 관리하는 모든 측면을 포괄하는 개념
- 데이터가 폐기되기 전까지 안전하고 효율적이며 경제적으로 활용되고 있는지 확인할 수 있음
데이터 수집
수집 방법
크롤링 및 WA(Web Analytics) 를 통해 수집된 데이터들을 원시 데이터(로우 데이터) 형태로 저장함
- Data Collector S/W (fluentd, logstash 등) 를 사용하여 온프레미스 데이터를 수집하는 방법
- 크롤러 (puppeteer, selenium 등) 를 사용하여 웹페이지(ex. 포털, 커뮤니티 등) 에서 데이터를 수집하는 방법
- 기 수집된 서드파티 데이터를 data lake 로 임포트하는 방법
데이터 관리
원시 데이터는 데이터 카탈로그를 작성하여 쿼리할 수 있음
- 데이터 카탈로그는 데이터 자체를 변환하여 저장하지 않고, 데이터의 메타데이터를 작성하여 저장하는 방식임
- 데이터 카탈로그는 AWS 의 Glue Data Catalog (Glue Crawler) 와 Hive Metastore 등의 호환 방식을 사용하는 방법이 있음
- Glue Data Catalog 는 Hive Metastore 형식과 호환되므로, 추후 Amazon EMR 과 통합할 수 있음
데이터 거버넌스에서는 가용성, 사용성 보장 외에도 데이터 보안 및 개인정보 보호도 중요한 역할을 함
- 다양한 유형의 데이터가 다양한 권한이나 규칙을 가질 수 있으며, 거기에 개인 식별 정보(PII)가 포함되는 경우도 있음
- 기업의 규제 준수 및 고객의 신뢰를 지킬 수 있음
- AWS Lake Formation 을 이용하면 강화된 IAM 정책을 사용하여 간편하게 액세스 권한을 관리할 수 있음
이 단계에서는 스토리지 비용이 저렴하며, 구조 및 시스템이 유연하므로 데이터의 구체적인 설계보다 수집에 중점을 두고 있음
- 다만 수집 범위의 명확한 설정이 없다면 불필요한 데이터가 많아져서, 데이터 및 메타데이터 관리에 어려움이 생길 수 있음
- data lake 운영에 대한 노하우가 없는 상태라면 요구 사항 충족을 우선으로 하여 구축해야 함
- 품질이 좋고, 기능 구현 목표에 부합하는 데이터 세트로 수집을 한정하여 data lake 관리 리스크를 줄일 수 있음
SSOT
여러 소스에서 수집된 데이터를 SSOT(Single Source Of Truth) 로 모으고, 싱크하는 작업이 필요함
- SSOT 는 S3 를 사용
- 데이터 업로드 배치 작업 및 싱크는 어떤 소스 저장소를 사용하는지에 따라 각각의 시나리오가 발생하며, 서드파티 S/W 의 사용을 고려해야 함
- 기본적으로 로컬 스토리지의 데이터는 AWS CLI 를 사용하여 간단히 배치 작업이 가능함
- 배치 작업이 커질 경우, kafka 등을 이용한 분산 처리가 필요할 수 있음
- 실시간 스트리밍 처리가 필요한 경우, AWS 는 Kinesis Firehose 라는 서비스로 데이터 스트리밍을 지원하고 있음
- 수집된 데이터가 있는 로컬 저장소 및 외부 저장소와 S3 를 효과적으로 싱크할 방안에 대해 고민이 필요
활용
데이터가 구조화되지 않더라도 원시 데이터 단계에서 분석 및 검색에 활용할 수 있음
- AWS Glue 및 Amazon Athena 를 활용한 데이터 쿼리
- Amazon Quicksight 를 통해 BI 분야에 활용
- 사전에 AWS Glue 를 통해 Data Catalog 가 생성되어야 함
- Amazon Sagemaker 및 AWS 의 AI 서비스에서 분석 및 활용
- Amazon Forecast 및 Amazon Personalize 등에서는 예측 분석에 활용
- ETL 및 data preparation 을 거치지 않은 데이터는 분석에 비효율적일 수 있음
- data preparation 을 AI 알고리즘으로 구현하여 데이터 거버넌스에 활용할 수 있음
- Amazon Forecast 및 Amazon Personalize 등에서는 예측 분석에 활용
관련 항목
- Data Lake
- BI & AI/ML
데이터 처리
data lake 에 저장된 원시 데이터를 구조화(정형화)된 데이터로 만들어, 빠르고 분석 용이한 형태로 만듬
RDBMS
- 쿼리 작업이 OLTP 의 성능 손실을 크게 주지 않는다면 RDBMS(OLTP) 에서 바로 분석 및 활용할 수 있음
- 일반적으로 data warehouse 등의 OLAP 을 구축하지 않고 OLTP 에서 쿼리나 집계를 실행하는 방식을 말함
data warehouse
- 데이터의 규모가 크고, 쿼리 작업이 트랜잭션 처리에 영향을 준다면 data warehouse 에 적재하여 활용하는 방법을 택해야 함
- OLTP 시스템에서 필요한 데이터를 추출하여 정제한 것이 데이터 웨어하우스이며, 이를 활용하는 수단이 OLAP 이다.
- AWS Redshift
- 최소 2개 이상의 노드로 구성된 클러스터 구조
- S3, DynamoDB, EMR, EC2 에서 데이터 업로드를 지원
- 입력을 위해서는 AWS 의 서비스인 GLUE 나 서드파티 ETL 도구를 활용해야 함
- RDBMS 와는 달리 데이터가 읽기 전용으로 입력됨
- 소스를 분산 저장하여 처리량을 높임
- S3 로 증분 백업 데이터를 자동 저장함
data processings
- data lake(S3) 의 데이터를 정제하거나, data warehouse 에 적재하기 위해서는 아래와 같은 작업을 거쳐야 함
- 데이터 파티셔닝
- ETL 작업
- 데이터 활용 목표에 따라 데이터 변환, 중복 데이터 제거
- 컬럼 기반 형식으로 데이터 재구성
- python, node.js, go 등으로 직접 코드를 작성하거나, AWS Glue Studio(Glue ETL) 을 활용하여 ETL 작업을 시행해야 함
- 데이터 및 작업 규모가 크다면 Amazon EMR(Hadoop, spark) 및 kafka 등의 분산 처리 시스템을 사용해야 함
- AWS Glue Studio 는 서버리스 Apache spark 기반의 서비스이므로 별도의 시스템 구축 없이 빅데이터를 처리할 수 있음
관련 항목
- Data Warehouse
- Data Analytics & Processing
데이터 분석 및 활용
BI
BI 는 Business Intelligence 의 약자로, 데이터를 통합/분석하여 기업 활동에 연관된 의사결정을 돕는 프로세스를 말함
- 여러 곳에 산재되어 있는 데이터를 수집하여 체계적이고 일목요연하게 정리함으로써 사용자가 필요로 하는 정보를 정확한 시간에 제공할 수 있는 환경
BI 프로세스를 지원하는 소프트웨어를 ‘BI 도구‘ 라고 함.
- BI 도구는 기업의 생산성 증가, 원가 절감, 고객 만족도 향상 등 기업 활동의 의사결정을 지원하고, 문제를 해결하는데 활용되고 있음
- 방대한 데이터의 수집과 분석 기법을 통해 객관적 정보를 바탕으로 합리적인 결정을 내릴 수 있도록 하는 이점이 있음
- 기업의 중요한 의사결정을 사람의 직관에 의존하지 않도록 함
BI 는 기간별, 영역별, 업무별로 데이터를 모으고 분석할 수 있을 뿐만 아니라, 예측 알고리즘을 통해 향후 변화(예측 분석)를 제시할 수 있음
- 계획을 세우거나, 미래의 문제에 대처하는 의사결정을 할 수 있음
- 기업의 마케팅, 영업, 고객서비스에서 필요한 입체적인 정보를 제공할 수 있음
AI/ML
AI 를 통해 개인화된 고객 경험 제공 및 보다 많은 데이터 기반의 의사결정을 내릴 수 있으며, 데이터를 AutoML 등에 활용하여 내부 데이터 품질 향상에 사용할 수 있음
데이터 분석 및 활용 분야에서 AI/ML 은 다음과 같은 사례로 활용됨
data lake 의 데이터 거버넌스를 향상시킴
- AI 알고리즘을 사용하여 빅데이터를 신속하게 선별하고, 중복 등의 관계를 식별 (data preparation)
- 자연어 처리를 통해 데이터 정의를 조정하고 구조화되지 않은 텍스트를 구조화하여 추가적인 인사이트를 제공할 수 있음
데이터 예측 분석 및 검색에 활용 및 BI 도구의 정확성을 높임
- AI 서비스 및 모델을 활용하여 데이터에 대한 보고, 예측 분석을 통해 인사이트를 생성
- 데이터 분석(검색)을 위해서는 특정 쿼리로 필터된 데이터 세트가 필요함
- Amazon Sagemaker 와 같은 AI 프레임워크
- Amazon Forecast, Amazon Personalize, Amazon Rekognition 등의 AI 서비스
AI/ML 모델 구축을 위한 훈련 데이터로 활용
- ML 모델 구축 및 배포를 위해 data lake 내의 수집 데이터를 활용
- 모델 생성을 위해서는 data lake 내의 원시 데이터를 data wrangling 을 통해 정제하는 과정이 필요
관련 항목
- BI & AI/ML
답글 남기기