
목차
- 개요
- 목적
- 인프라 수명 주기
- 백업 정책
- 복구 정책
- 시행 기준
개요
모든 상용 서비스는 장애 및 데이터 결손 상황을 대비해 원 서비스로 복구할 수 있도록 해야 한다.
이를 위해 데이터 및 운영 환경이 백업되어 있어야 하고, 이 백업 데이터를 관리하고 복구 시에 사용할 정책 및 시나리오가 작성되어야 한다.
아래 문서에서는 AWS 인프라의 백업 및 복구 정책과 실제 운용 방법에 대해 기술하였다.
목적
해당 문서에서는 아래의 사항에 대해 충족되어야 한다.
아래 내용은 모두 AWS 인프라 내에서의 정책으로 한정된다.
- 백업 및 복구에 대한 전반적인 정책
- 백업 데이터의 생성 기준 및 관리 정책
- 백업 및 복구 정책을 시행할 대상
- 백업 데이터의 생성 및 관리를 위한 환경 구성
- 복구 시행 정책 및 시나리오
- 백업 데이터의 생성, 복구 테스트 작업 시행
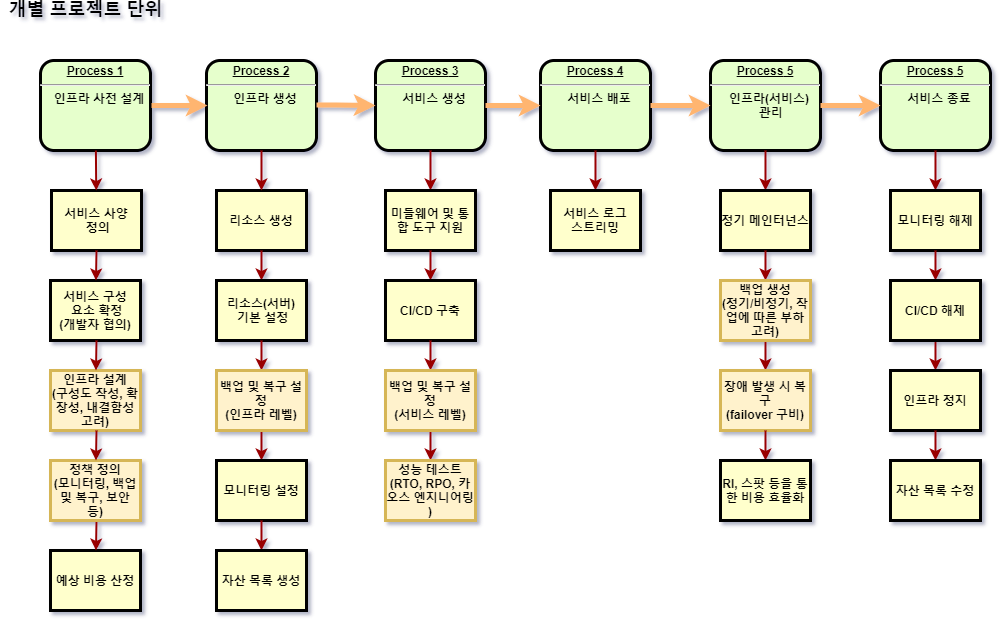
인프라 수명 주기
인프라는 서비스가 시작되고, 종료되는 일정 수명 주기 속에서 이에 대한 여러 작업들이 있음.
이 작업 흐름 속에서 백업 및 복구 정책은 언제 작성되고, 적용되며, 서비스의 어느 단계에서 영향을 미치는지 파악할 필요가 있음
인프라 사전 설계
- 인프라 사전 설계 단계에서 SLA/SLI 에 따른 확장성 및 내결함성에 대한 부분이 포함되면, 백업 및 복구 정책을 더욱 유연하게 할 수 있음
- 백업 및 복구에 대한 정책이 사전에 작성되어야 하며, 개발 및 운영 담당자와 합의되어야 함.
인프라(서비스) 생성
- 백업 및 복구 정책은 인프라 레벨과, 서비스 레벨에서 각각 적용됨
- 복구 시간(RTO), 복구 시점(RPO) 에 대해 서비스 생성 단계에서 사전 테스트가 진행되어야 함.
인프라(서비스) 관리
- 서비스 관리 단계에서 사전 정의 및 적용된 백업 정책에 의한 작업이 이루어짐 (정기/비정기)
- 백업 데이터 생성에 대한 부하를 고려하여, 데이터 생성 시간에 대해 개발 및 운영 담당자와 합의되어야 함.
- 복구 시간(RTO), 복구 범위(RPO) 에 대해 개발 및 운영 담당자에게 사전 고지가 되어야 함.
- 백업 및 복구 정책에 장애 극복 기능(failover) 이 포함되어 있다면, RTO/RPO 를 더욱 유연하게 가져갈 수 있음
백업 정책
백업이라 함은 운영 중인 서비스의 관련 데이터 및 미들웨어, APP 의 설정에 대해 해당 서비스의 로컬 스토리지가 아닌 외부 스토리지 등에 보관함을 말함
대상 데이터에 대해 크게 나누면 아래와 같다.
- 시스템 전체 이미지의 snapshot 파일
- Database 의 SQL dump 파일 및 스토리지의 snapshot 파일
- NGINX, PHP 등 미들웨어의 설정 파일
- APP 의 설정 파일 및 (경우에 따라) 정적 콘텐츠 파일
- 그 밖에 커스터마이징된 플러그인, 모듈, 라이브러리 등의 파일
백업에는 데이터를 생성 및 관리하는 공수와 데이터 보관 비용이 포함되기 때문에, 모든 서비스에 대해 백업 데이터를 보관하기는 현실적으로 어려움
따라서 백업 정책이 적용될 대상을 정하는 기준을 세워, 꼭 필요한 데이터만을 보관하도록 함
그리고 해당 대상에서도 중요도 및 서비스 특수성을 감안하여 백업 범위, 보관 기간에 대하여 차이를 두어야 함
복구 정책
복구라 함은 운영 중인 서비스의 장애 및 데이터 결손으로 인해 정상 서비스가 불가능할 경우, 정상 서비스 상태로 되돌리기위한 작업을 말함
복구 방법을 크게 나누면 아래와 같다.
해당 문서에는 데이터 복구에 대한 정책을 작성하였음.
데이터 복구
- 일부 혹은 전체 데이터의 결손이 발생할 경우, 백업 데이터로 교체함
- 특정 시점으로 롤백이 필요한 경우, 특정 시점(Point-In-Time) 복구를 시행함
서비스 복구
- 서비스 전체에 장애가 발생하여 새로운 리소스로 복구할 경우, 백업 데이터를 사용하여 서비스를 마이그레이션함
- 다운타임을 최소화 혹은 제로로 만들 수 있는 구조로 서비스를 설계함
- 내결함성이 필요한 서비스의 경우 failover (장애 조치 기능) 가 가능하도록 설계함
- DNS Routing(Route53), Auto Scaling, CloudWatch Alarm 등
- 이중화, 클러스터링 등을 활용하여 고가용성 구조로 설계함
- ELB, Read Replica, Multi-AZ, Serverless 등
- 내결함성이 필요한 서비스의 경우 failover (장애 조치 기능) 가 가능하도록 설계함
시행 기준
리소스별 정책
- AWS 서비스 특성상, 백업이 필요없는 리소스에 대해서는 작성하지 않음 (Ex. EFS, S3)
- 리소스 특성상, 백업이 필요없는 리소스에 대해서는 작성하지 않음 (Ex. ElastiCache)
| 대상 리소스 | 내용 | 백업 방법 | 복원 방법 |
| EC2 Instance (EBS) | 기본적으로 EBS(로컬 디스크)에 대해 백업을 시행할 필요가 없으나, 다음의 경우 백업이 필요할 수 있음
서비스의 즉각적인 복구가 필요한 경우 리소스가 HA 구성이 되지 않았거나, 마이크로서비스화 되지 않은 경우 서비스 중단 상황을 최소화 할 수 있음 |
EBS Snapshot | 신규 EC2 Instance 생성
신규 EBS 생성 |
| RDS (MySQL) | 기본적으로 RDS 의 Auto Backup 을 이용하나, 다음의 경우 별도의 snapshot 생성이 필요할 수 있음
Database 의 버전 업그레이드 작업이 있을 경우 APP 서비스의 대형 업데이트 등 다량의 수정 사항 발생 시 |
RDS Snapshot
mysqldump 등의 백업 도구 |
특정 시점으로 롤백
신규 DB 로 마이그레이션 dump 파일에서 복원 |
| Elasticsearch | 기본적으로 스토리지 백업이 필요가 없으나, 다음의 경우 수동으로 백업이 필요할 수 있음
클러스터의 버전 업그레이드 작업이 있을 경우 인덱스 및 샤드 정리 작업이 필요할 경우 |
Snapshot (S3)
인덱스 데이터 백업 |
AES API 로 복원
데이터 덮어쓰기 |
| Static Data | 로컬 디스크 사용량이 많을 경우 EFS, S3 등의 원격 스토리지 사용을 권장함.
기본적으로 정적 데이터를 백업할 필요가 없으나, 다음의 경우 수동으로 백업이 필요할 수 있음 사용자 데이터를 DB 가 아닌 로컬 스토리지에 저장하는 방식일 경우 (Ex. 워드프레스) 커스터마이징한 (수정 사항이 많은) 미들웨어 및 APP 프로그램 소스 코드가 형상 관리되지 않는 경우 |
데이터 백업
형상 관리 도구 이용 |
데이터 덮어쓰기 |
형상별 정책
형상별 특징
| 형상 | 특징 |
OP |
외부로 노출된 퍼블릭 서비스들이 위치함
장애 상황에 대해 빠른 복구가 필요함 저장된 데이터의 결손이 절대 발생해서는 안됨 |
MGMT |
관리, 업무 지원, 모니터링을 위한 서비스들이 위치함
외부, 내부 서비스들이 모두 존재함 장애 상황에 대해 빠른 복구가 필요함 저장된 데이터의 결손이 가급적 발생해서는 안됨 |
| DV | 개발 및 테스트용 리소스들이 위치함
담당자에게 공유된 상황이라면 장애가 발생해도 무관함 한시적이거나 테스트용 데이터들을 다룸 |
답글 남기기